
넘스탯
DATA ANALYTICS & INSIGHTS
확률에서 LLM까지 – 데이터 사이언스 전문 교육 플랫폼
비슷한 것끼리 묶어라 — 단, 정답은 아무도 알려주지 않는다
이 페이지에서 배우고 나면
- 데이터가 K개의 군집으로 나뉘는 과정을 단계별로 관찰할 수 있습니다.
- K를 바꾸면 결과가 어떻게 달라지고, 적절한 K를 어떻게 고르는지(엘보우 등) 이해할 수 있습니다.
- 초기 중심점 위치에 따라 결과가 달라질 수 있음을 직접 확인할 수 있습니다.
📉 Elbow Method — WCSS의 꺾이는 지점
WCSS(K) = Σᵢ Σx∈Cᵢ ‖x − μᵢ‖²는 각 cluster 내 점-중심 거리의 제곱합입니다. K가 증가하면 항상 감소하지만, 감소율이 급격히 줄어드는 지점("팔꿈치")이 자연스러운 K입니다.
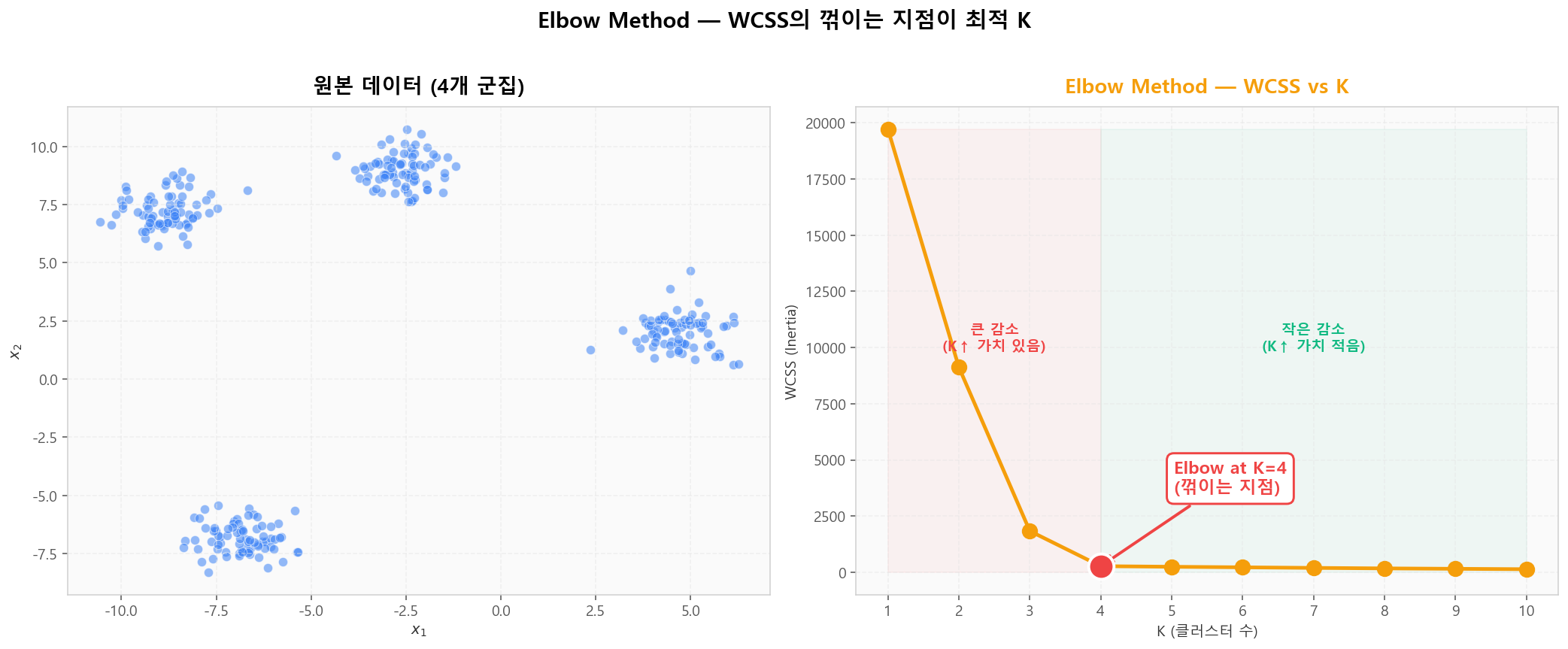 Elbow Method — WCSS의 꺾이는 지점이 최적 K
Elbow Method — WCSS의 꺾이는 지점이 최적 KSilhouette 정의 — a(i), b(i), s(i)
Rousseeuw (1987)의 Silhouette는 점 i에 대해 두 거리를 비교합니다: a(i)는 자기 cluster 내 평균 거리(응집), b(i)는 가장 가까운 다른 cluster까지 평균 거리(분리). s(i) = (b(i) − a(i)) / max(a(i), b(i))는 [−1, 1] 범위로 1에 가까울수록 잘 분리된 cluster입니다.
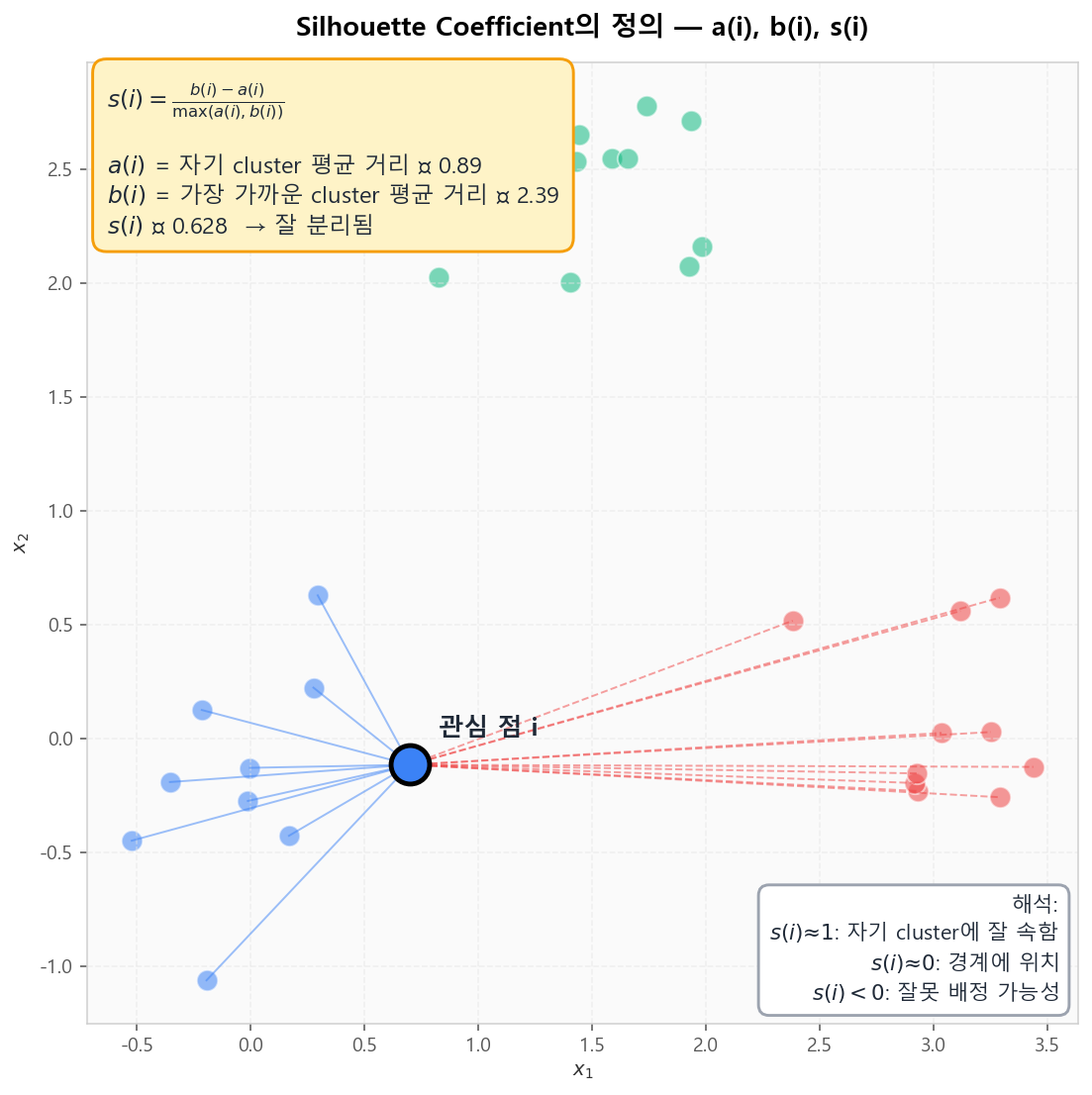 Silhouette Coefficient 정의 — Rousseeuw (1987)
Silhouette Coefficient 정의 — Rousseeuw (1987)Silhouette Plot — 클래식 시각화
각 점의 s(i)를 cluster별로 정렬해 가로 막대로 그린 것이 Silhouette Plot입니다. "두께가 균일한 칼날 모양"이 좋은 클러스터링, 어떤 cluster가 짧거나 s(<0)인 점이 많으면 K 조정 또는 다른 알고리즘이 필요합니다.
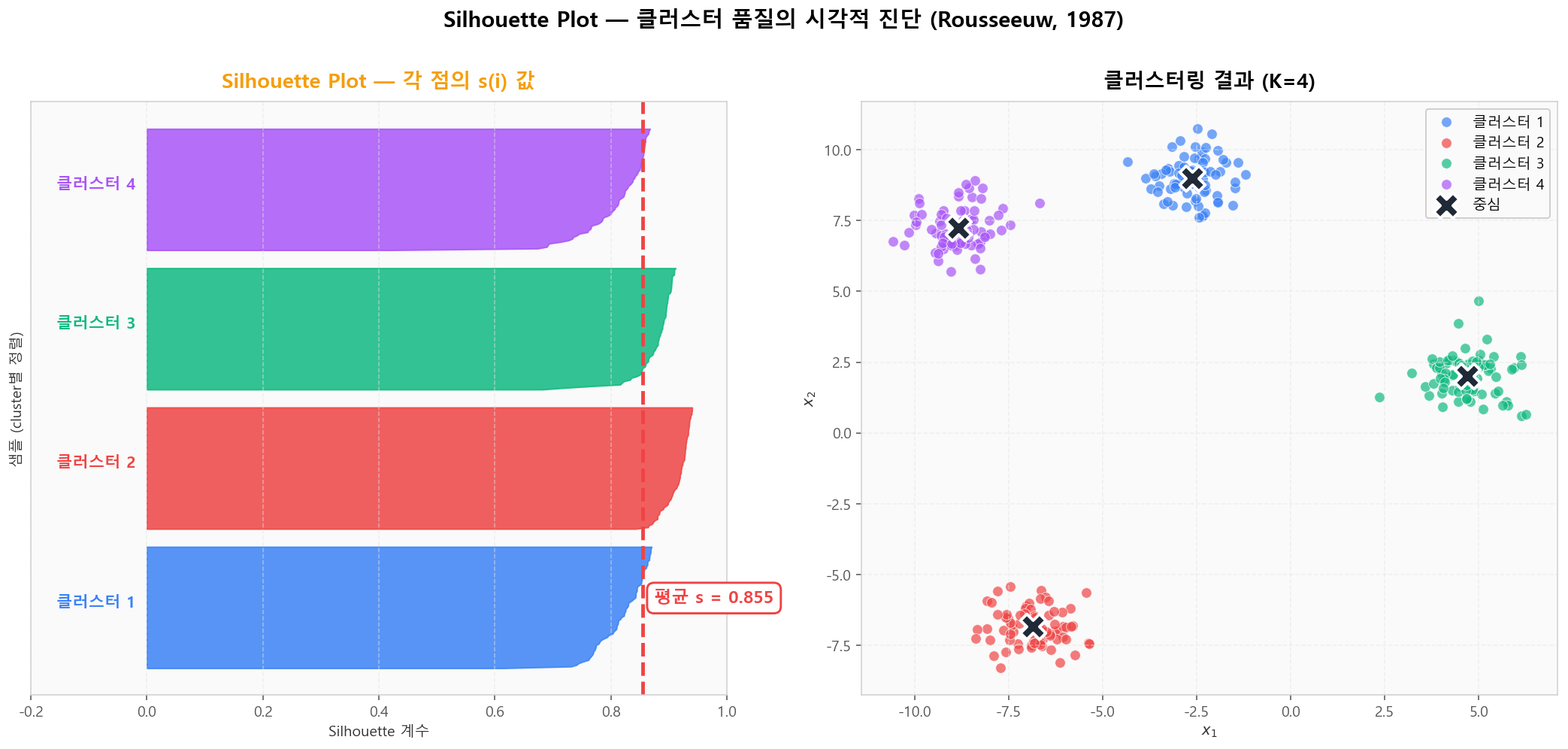 Silhouette Plot — Rousseeuw의 클래식 시각화
Silhouette Plot — Rousseeuw의 클래식 시각화K별 Silhouette Score 비교
여러 K로 K-Means를 돌린 뒤 평균 Silhouette Score를 비교합니다. 최댓값을 갖는 K가 권장됩니다. Kaufman & Rousseeuw (1990)의 해석 기준: >0.7 강한 구조 / 0.5~0.7 합리적 / 0.25~0.5 약함 / <0.25 구조 거의 없음.
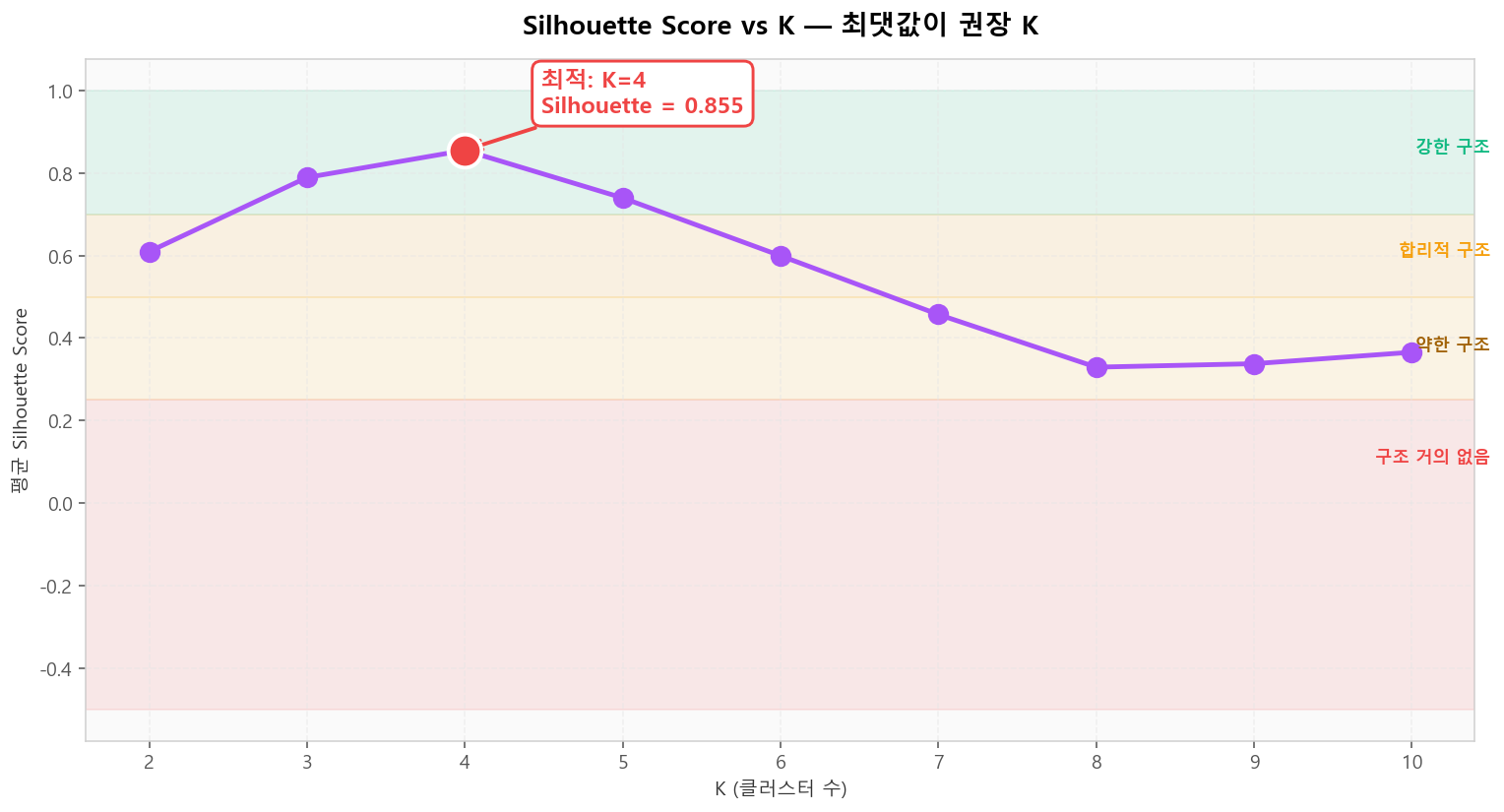 K별 Silhouette Score — 최댓값을 갖는 K가 권장
K별 Silhouette Score — 최댓값을 갖는 K가 권장Elbow + Silhouette 결합 평가
두 지표가 같은 K를 가리킬 때 결정의 신뢰도가 높아집니다. 다를 때는 데이터 구조 점검·도메인 지식·Gap Statistic(Tibshirani et al. 2001) 등의 보조 지표를 추가로 사용합니다.
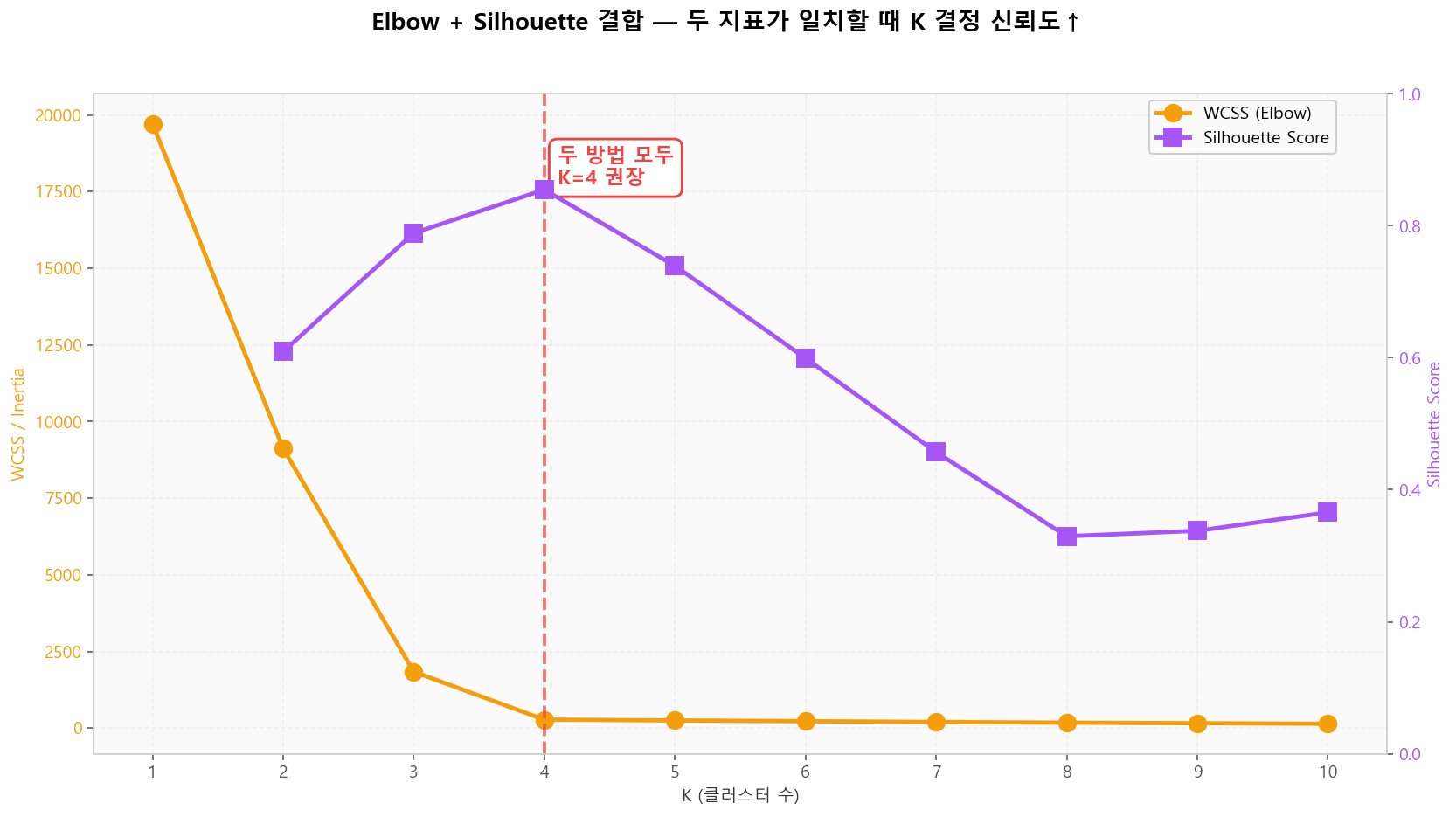 Elbow + Silhouette 결합 — 일치 시 신뢰도 ↑
Elbow + Silhouette 결합 — 일치 시 신뢰도 ↑K-Means 평가 인터랙티브 — Elbow + Silhouette
데이터셋을 선택하고 K=1~10 범위에서 두 평가지표를 동시 비교하세요. 두 방법이 같은 K를 가리키면 신뢰도가 높습니다. (Rousseeuw 1987의 Silhouette 정의 사용)
데이터셋 (실제 군집 수)
K 최댓값 = 10
Elbow (WCSS)
Silhouette Score
🎮 K-Means 알고리즘 시각화 랩 (Lloyd's Algorithm)
위 평가지표로 K를 정한 뒤, 실제 K-Means 알고리즘이 step-by-step으로 어떻게 수렴하는지 아래에서 시각적으로 확인하세요.
K 선택 휴리스틱 비교
Elbow Method
장점: 직관적, 계산 빠름. 단점: "꺾이는 지점"이 주관적이고, 매끄러운 데이터에서는 명확한 elbow가 없음.
Silhouette Score
장점: 객관적 수치 비교 가능. 단점: O(n²) 거리 계산으로 느림. 큰 데이터에서는 샘플링 사용.
Gap Statistic
Tibshirani et al. (2001) — null reference 분포와 WCSS 차이를 통계적으로 비교. 가장 엄밀하지만 비용 큼.
BIC / AIC (GMM)
확률 모델 가정 시 적용 가능. K-Means는 결정론적이라 직접 적용 불가, GMM에서는 표준.
직접 해보기 — 실습 과제
- 정답 K 맞히기: '4 군집' 선택. Elbow와 Silhouette 모두 K=4를 가리키는지 확인
- 구조 없는 데이터의 한계: '무작위' 선택. Silhouette 점수가 모든 K에서 낮게 유지 → K-Means가 적합하지 않은 신호
- 두 방법 비교: 동일 데이터에서 Elbow와 Silhouette의 권장 K가 다른 경우가 있다면 — 어느 쪽을 따를지 결정 근거 정리
- 알고리즘 시각화: 평가지표로 K=4를 선택한 뒤 아래 K-Means Lab에서 K=4로 실제 알고리즘이 어떻게 수렴하는지 step-by-step 관찰
📖 더 깊이 학습하기
- Rousseeuw (1987): "Silhouettes: a graphical aid to the interpretation and validation of cluster analysis", Journal of Computational and Applied Mathematics
- Kaufman & Rousseeuw (1990): "Finding Groups in Data" — Silhouette 해석 기준 표준 교재
- Tibshirani, Walther, Hastie (2001): "Estimating the number of clusters in a data set via the gap statistic", JRSS-B
- Hastie, Tibshirani, Friedman, ESL (2009) — Ch.14.3: 클러스터링 평가 종합
- scikit-learn 문서: sklearn.metrics.silhouette_score, KMeans