
넘스탯
DATA ANALYTICS & INSIGHTS
확률에서 LLM까지 – 데이터 사이언스 전문 교육 플랫폼
PCA 실습실 — 주성분 분석
"100차원을 2차원으로 squeeze, 변동성 큰 축만 살려" — 차원 축소의 표준
원하는 개념·랩·가이드를 검색해보세요
Ctrl K수십 개 특징을 2개로 줄여도 그림이 보인다
이 페이지에서 배우고 나면
- 여러 특징을 분산이 가장 큰 방향으로 압축하는 과정을 직접 볼 수 있습니다.
- 몇 개 축으로 원본 정보의 얼마를 보존하는지(설명 분산) 확인할 수 있습니다.
- 차원을 줄이면 정보가 일부 손실된다는 점을 실험으로 이해할 수 있습니다.
주성분 = 분산이 최대가 되는 새 축
PCA의 핵심 아이디어는 단순합니다 — 데이터를 새로운 좌표계로 회전했을 때 각 축의 분산이 최대가 되는 방향을 찾는 것입니다. 빨간 화살표(PC1)는 가장 많이 흩어지는 방향, 주황 화살표(PC2)는 그에 수직이면서 두 번째로 많이 흩어지는 방향입니다.
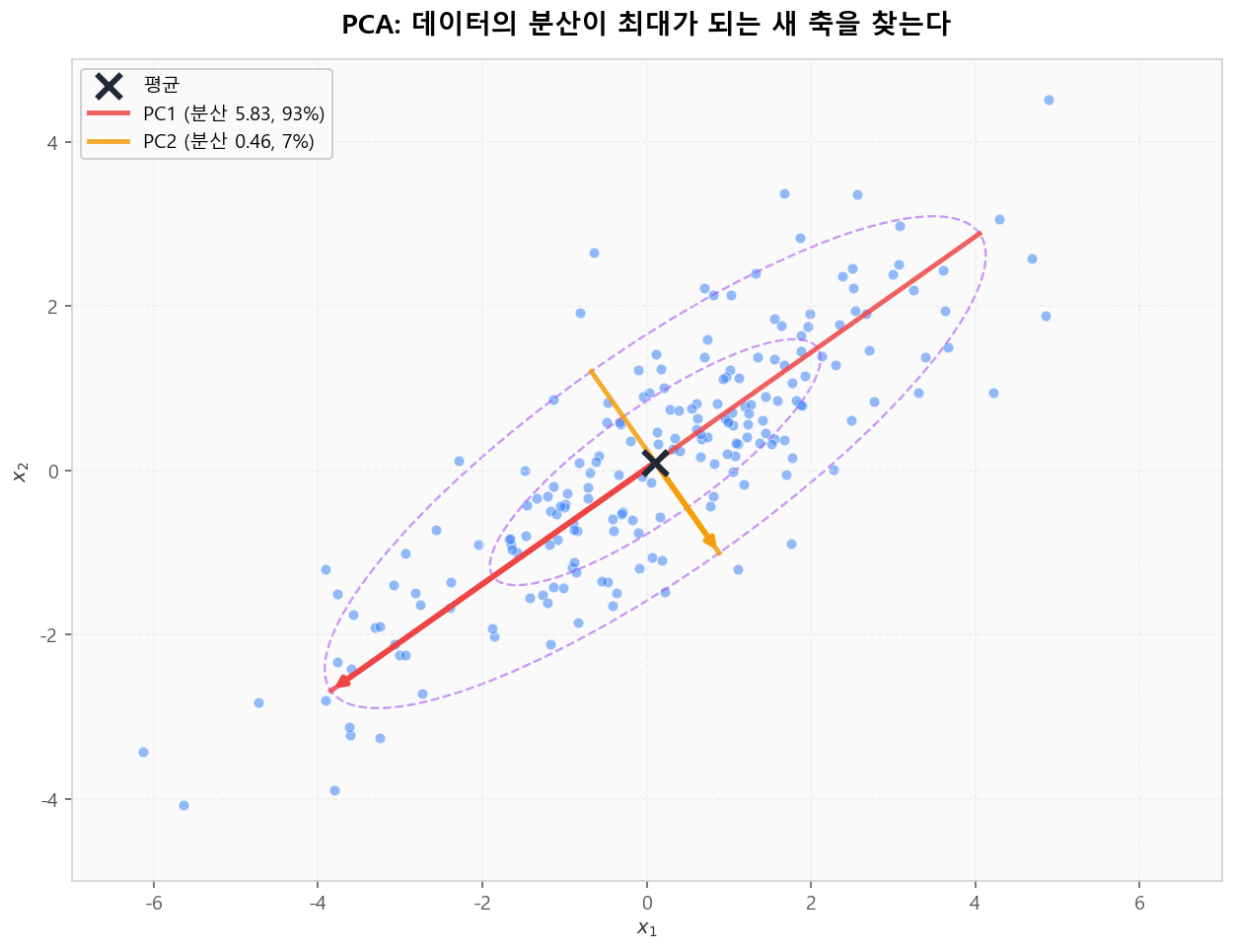 PC1·PC2는 데이터의 분산이 최대가 되는 직교 축
PC1·PC2는 데이터의 분산이 최대가 되는 직교 축PCA의 수학 — 공분산 행렬의 고유분해
PCA는 데이터의 공분산 행렬 Σ를 고유분해합니다. 고유벡터가 주성분 방향이고, 고유값 λ가 해당 축의 분산입니다. 큰 순으로 정렬된 고유값들의 누적 합이 설명 분산이 됩니다.
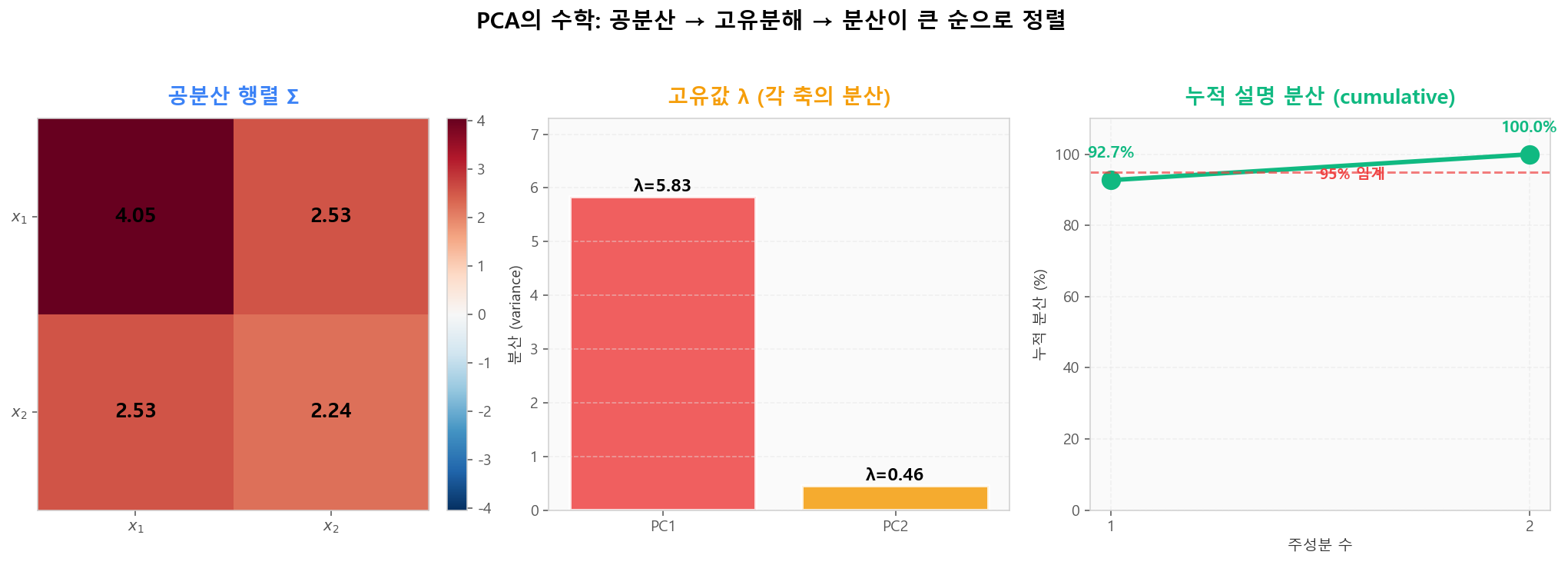 공분산 행렬 → 고유분해 → 분산이 큰 순으로 정렬
공분산 행렬 → 고유분해 → 분산이 큰 순으로 정렬PCA 인터랙티브 — 주성분 시각화
2D 데이터의 회전·잡음을 조정하며 주성분 PC1·PC2가 어떻게 결정되는지 실시간으로 관찰하세요. 공분산 행렬의 고유분해 결과가 빨간 화살표(PC1)·주황 화살표(PC2)로 표시됩니다.
데이터셋
회전 각도 = 35°
잡음 σ = 0.30
2D 데이터 + 주성분 축
분산 설명 비율 (Scree)
PC1 위로 1D 사영 (히스토그램)
📉 Scree Plot — 몇 개의 PC를 쓸까?
실무에서 가장 큰 질문은 "차원을 몇 개로 줄일까?"입니다. Scree plot은 각 PC의 고유값을 크기 순으로 그린 차트로, 꺾이는 지점(Elbow) 또는 누적 분산 95% 임계를 기준으로 K를 정합니다.
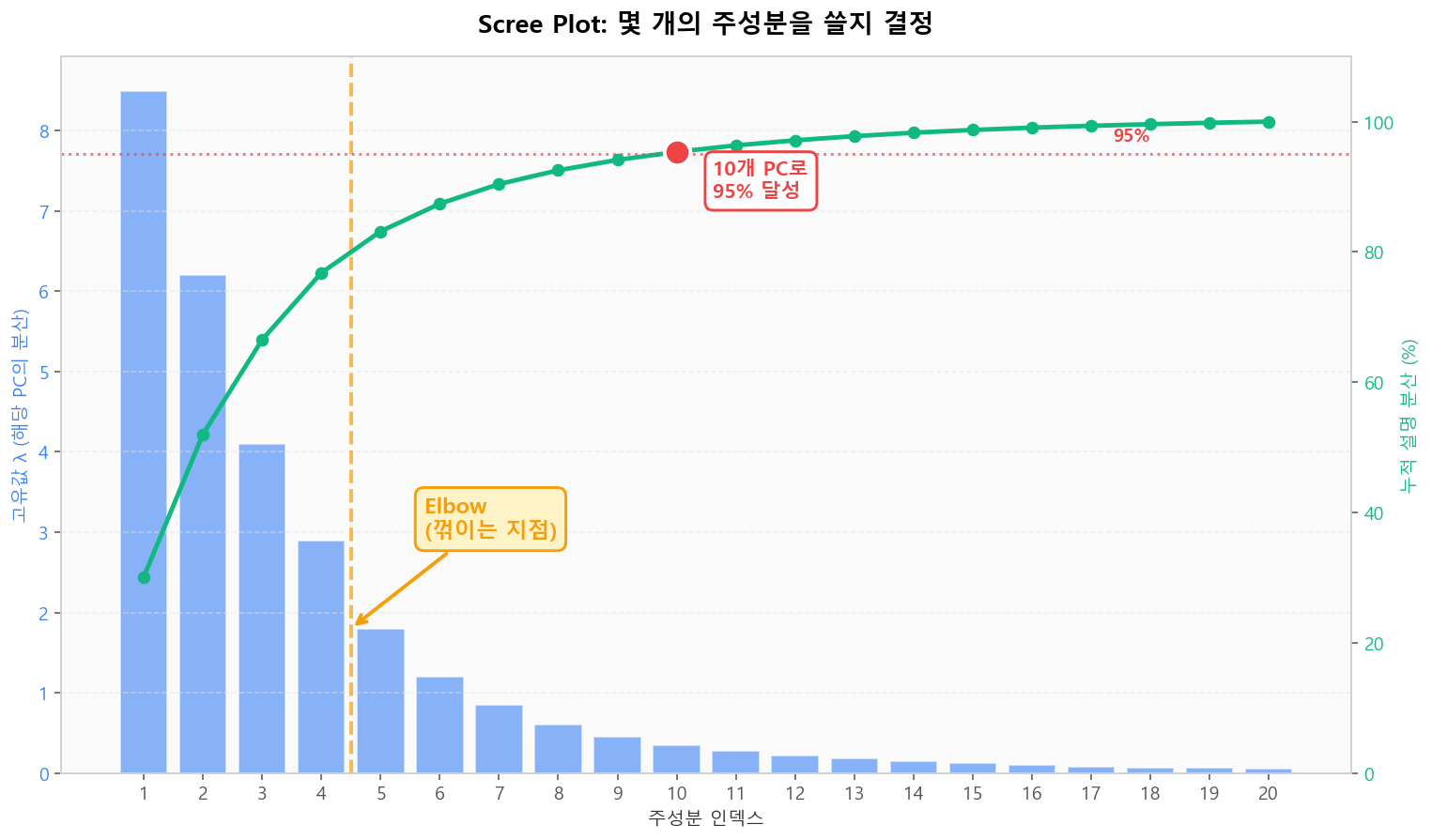 Scree plot — Elbow와 95% 임계로 적정 차원 결정
Scree plot — Elbow와 95% 임계로 적정 차원 결정고차원 데이터 → 2D 시각화
사람은 3차원 이상을 직관적으로 볼 수 없습니다. PCA는 고차원 데이터의 처음 2~3개 주성분을 추출해 2D/3D 산점도로 시각화하는 표준 도구입니다. 임의의 두 차원보다 PC1·PC2가 클래스 분리를 훨씬 잘 보여줍니다.
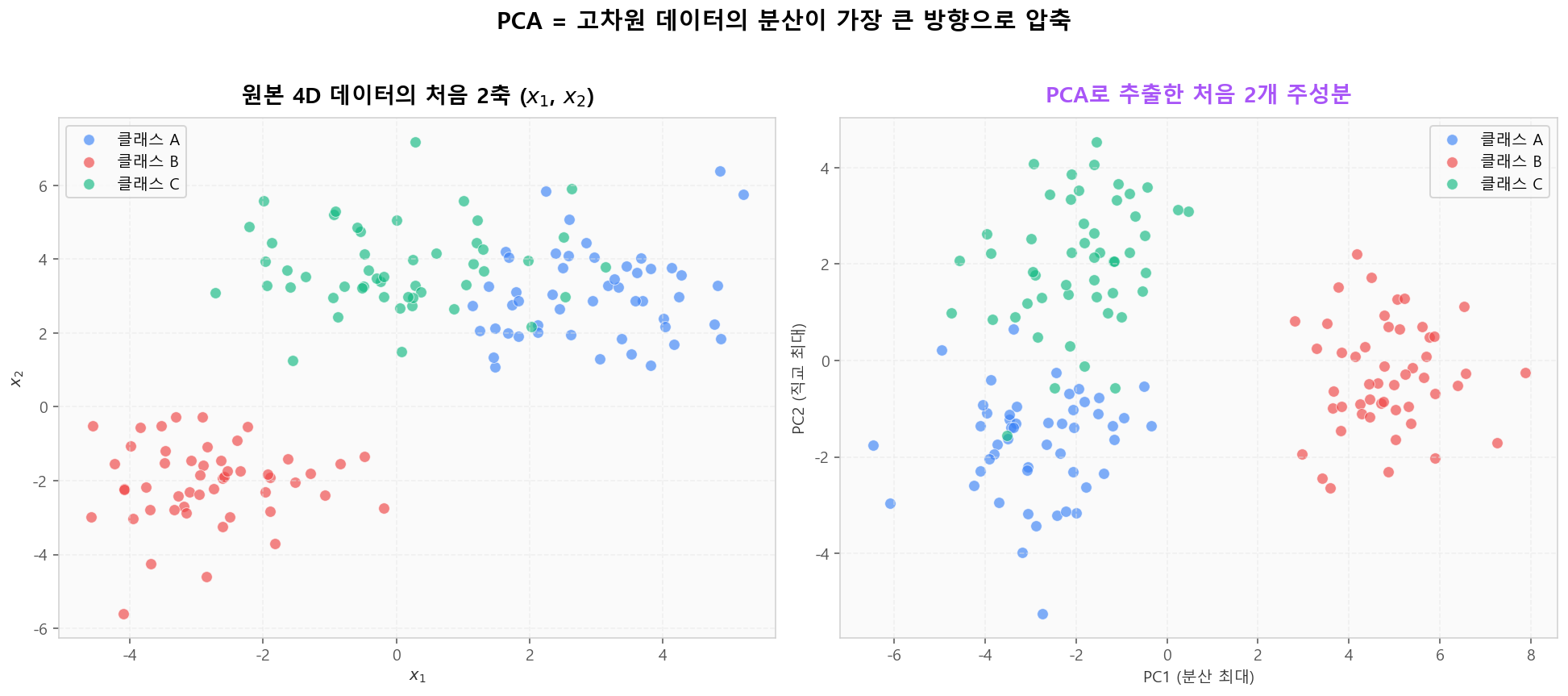 4D 데이터의 원본 2축 vs PCA 후 2D — 클래스 분리가 뚜렷해진다
4D 데이터의 원본 2축 vs PCA 후 2D — 클래스 분리가 뚜렷해진다이미지 압축 — 256차원 → K차원 → 복원
16×16 = 256차원의 얼굴 이미지를 PCA로 K개 주성분으로 압축한 뒤 복원합니다. K가 작아도 분산을 많이 보존하는 주성분만 살아남으면 시각적으로 거의 비슷한 이미지를 복원할 수 있습니다 — JPEG/Eigenface의 핵심 원리.
 PCA 이미지 압축: 256D → K=3, 8, 30, 100 PC로 복원
PCA 이미지 압축: 256D → K=3, 8, 30, 100 PC로 복원PCA 사용 가이드
PCA를 쓰면 좋은 경우
- 특징 간 강한 상관관계 (다중공선성)
- 고차원 데이터의 시각화 (2D/3D)
- 노이즈 제거 (작은 PC 버림)
- 압축 (이미지·음성)
- 선형 모델의 전처리
PCA의 한계
- 선형: 비선형 구조(동심원·나선) 처리 불가 → Kernel PCA, t-SNE, UMAP
- 스케일에 민감 → 사용 전 표준화 필수 (StandardScaler)
- 분산 ≠ 정보: 분산 큰 축이 항상 유용한 정보는 아님
- 결과 PC의 의미 해석 어려움 (원본 특징의 선형 결합)
직접 해보기 — 실습 과제
- 회전 불변성: '상관 있는 정규' 선택, 각도 슬라이더를 0°~180°로 옮겨보세요. PC1은 항상 분산 최대 방향을 따라갑니다 — 좌표계 회전에 영향받지 않는 것이 PCA의 핵심 장점.
- 잡음 → PC2 비율 증가: 잡음을 0.05 → 1.5로 키우면 데이터가 둥글어져 PC2의 분산 비율이 커집니다. 분산 비율 차트로 확인.
- 2 클러스터의 사영: '2개 클러스터' 데이터셋. PC1이 두 클러스터를 잇는 방향이 되어 1D 사영 히스토그램이 bimodal로 나타남.
- PCA의 한계 체감: '동심원' 데이터셋. PC1·PC2가 의미를 잃고, 1D 사영에서 두 원이 섞입니다 — Kernel PCA나 t-SNE가 필요한 상황.
📖 더 깊이 학습하기
- Bishop, Pattern Recognition and Machine Learning (Springer 2006) — Ch.12: PCA의 확률적 해석(PPCA)과 EM 알고리즘
- Hastie, Tibshirani, Friedman, ESL (2009) — Ch.14.5: PCA·ICA·NMF 비교
- Pearson (1901): PCA 원논문 — "On lines and planes of closest fit to systems of points in space"
- Schölkopf et al. (1998): Kernel PCA — 비선형 차원 축소
- van der Maaten & Hinton (2008): t-SNE — 시각화 특화 비선형 임베딩