
넘스탯
DATA ANALYTICS & INSIGHTS
확률에서 LLM까지 – 데이터 사이언스 전문 교육 플랫폼
DBSCAN 실습실 — 밀도 기반 클러스터링
"K-means는 동그란 모양만, DBSCAN은 밀도로 모아" — 모양 무관 + 노이즈 자동 탐지
원하는 개념·랩·가이드를 검색해보세요
Ctrl K동그랗지 않은 군집도, 노이즈도 찾아내는 클러스터링
이 페이지에서 배우고 나면
- 밀도 기반으로 군집을 찾는 원리를 직접 관찰할 수 있습니다.
- K-means로는 못 찾는 형태의 군집을 DBSCAN이 어떻게 잡는지 비교할 수 있습니다.
- 어떤 점이 노이즈로 분류되는지, 파라미터가 그 경계를 어떻게 바꾸는지 확인할 수 있습니다.
K-means vs DBSCAN — 본질적 차이
초승달(moons) 데이터에서 두 알고리즘의 차이가 극명히 드러납니다. K-means는 구형 클러스터를 가정하므로 초승달을 잘못 가르고, DBSCAN은 밀도로 연결된 점들을 따라가며 모양 무관으로 정확히 분리합니다.
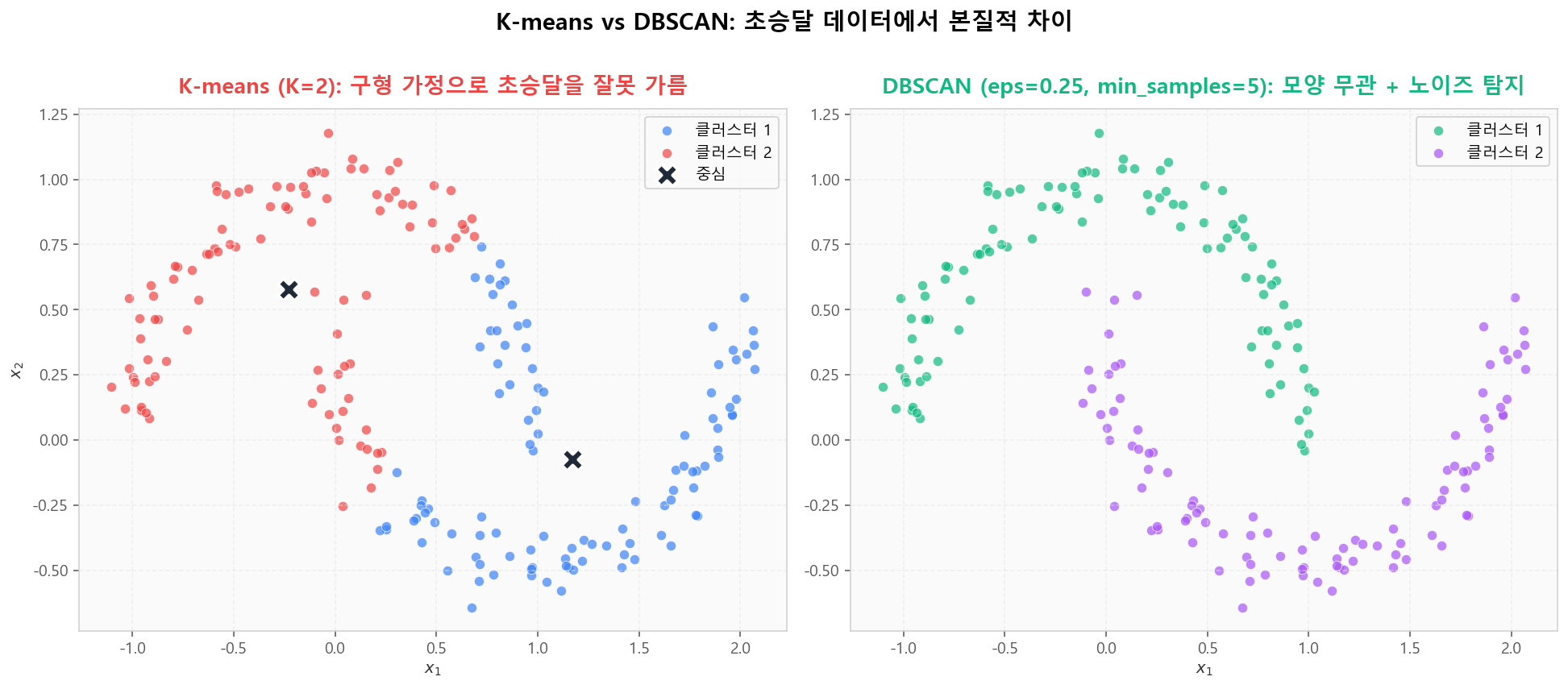 K-means는 구형 가정 / DBSCAN은 밀도 기반 — 초승달에서 차이 명확
K-means는 구형 가정 / DBSCAN은 밀도 기반 — 초승달에서 차이 명확DBSCAN의 3가지 점 유형
DBSCAN은 모든 점을 3가지로 분류합니다: (1) Core: 반경 eps 안에 min_samples개 이상 이웃이 있는 점, (2) Border: 자신은 core가 아니지만 core의 이웃, (3) Noise: 그 어느 쪽도 아닌 외딴 점. 이 단순한 분류가 클러스터의 모양과 노이즈를 동시에 다룹니다.
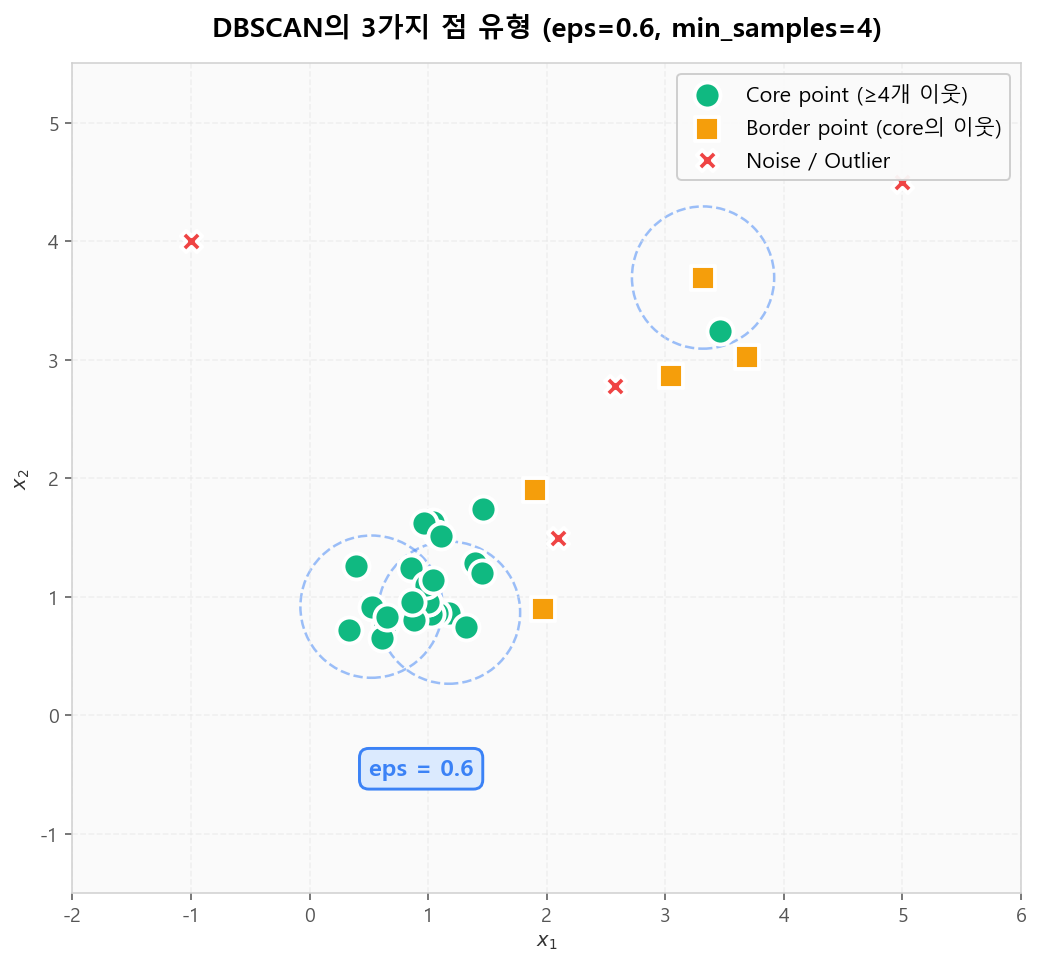 Core / Border / Noise — 단순한 3분류로 임의 모양 클러스터링
Core / Border / Noise — 단순한 3분류로 임의 모양 클러스터링DBSCAN 인터랙티브 — 밀도 기반 클러스터링
eps와 min_samples 슬라이더를 조절하며 클러스터·노이즈가 어떻게 변하는지 실시간 관찰. 점 위에 마우스를 올리면 eps 반경 원이 표시됩니다.
데이터셋
eps (반경) = 0.25
너무 작으면 모두 noise, 너무 크면 모두 1 clustermin_samples = 5
core point의 최소 이웃 수데이터 점 수 = 180
🔧 eps 하나가 결과 전체를 결정
eps가 너무 작으면 거의 모든 점이 noise, 너무 크면 모두 하나의 클러스터로 묶입니다. 그래서 eps 튜닝이 DBSCAN의 성패를 좌우합니다.
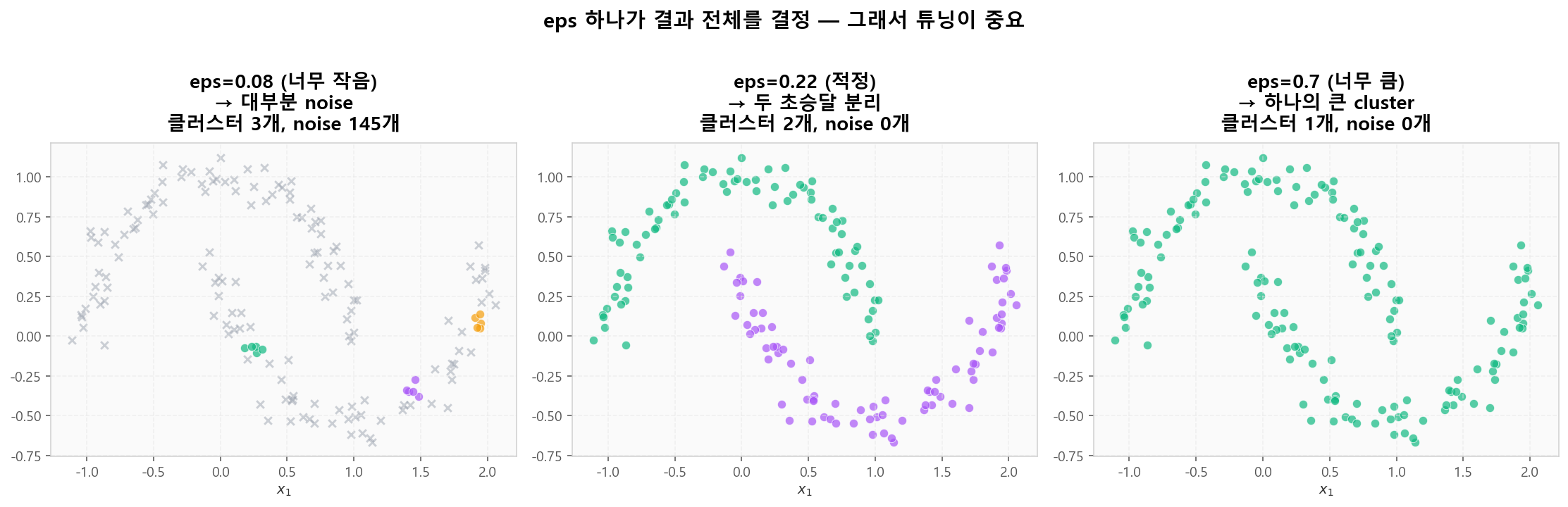 eps에 따른 결과 변화 — 너무 작음 / 적정 / 너무 큼
eps에 따른 결과 변화 — 너무 작음 / 적정 / 너무 큼eps 선택 휴리스틱 — k-distance Plot
실무에서 eps는 어떻게 정할까요? k-distance plot이 표준 휴리스틱입니다. 각 점의 k번째 최근접 이웃까지의 거리를 오름차순으로 그린 뒤, 가장 가파르게 꺾이는 지점(Elbow)의 거리값을 eps로 사용합니다.
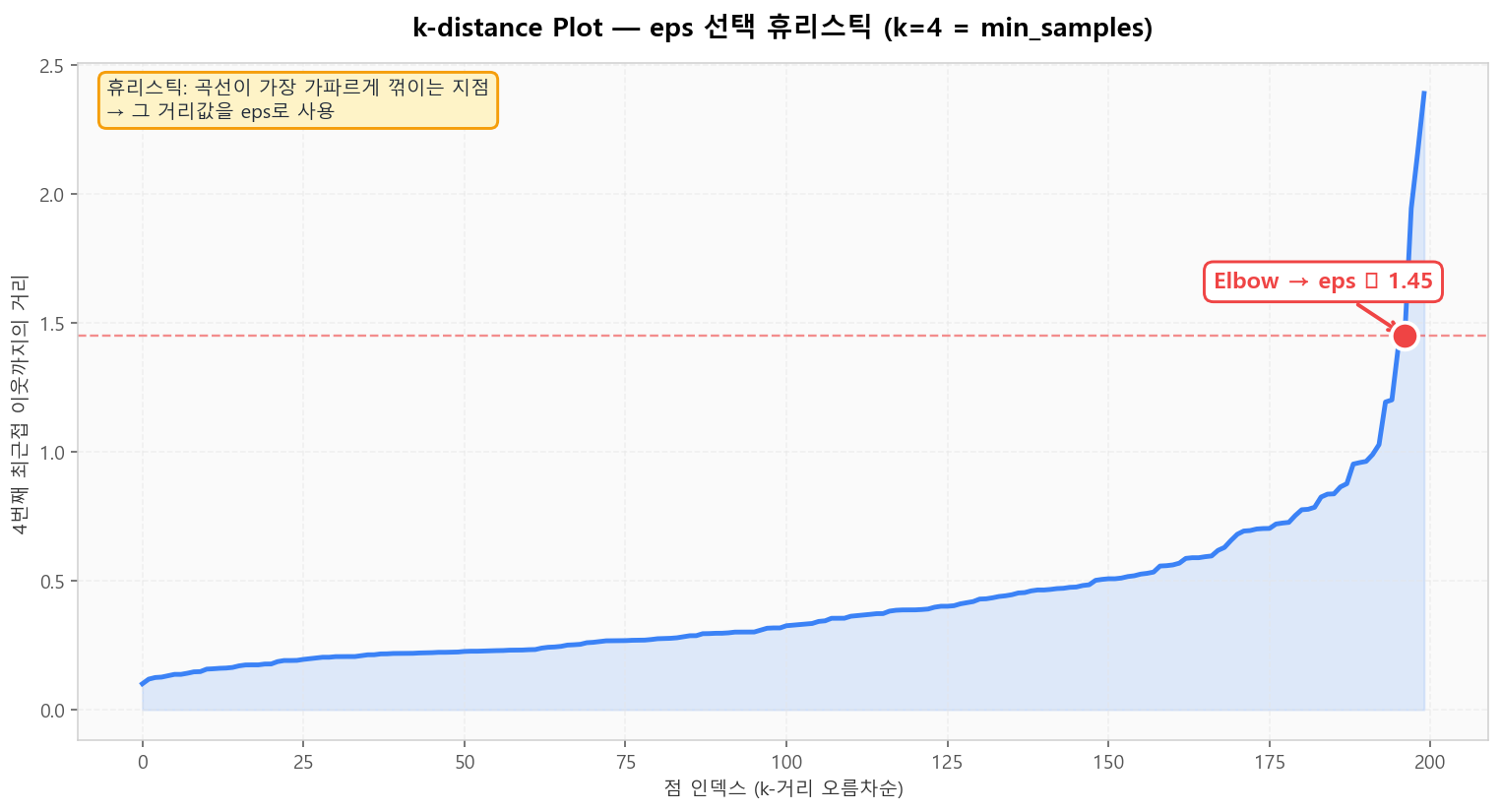 k-distance plot — Elbow의 거리값을 eps로 선택
k-distance plot — Elbow의 거리값을 eps로 선택DBSCAN의 한계 — 밀도가 다른 클러스터
밀도가 크게 다른 두 클러스터를 동시에 처리하기 어렵습니다. 어떤 eps를 써도 한쪽에 최적화하면 다른 쪽이 깨집니다. 해결책: HDBSCAN(계층적 밀도 기반) 또는 OPTICS(eps 자동 변화)를 사용합니다.
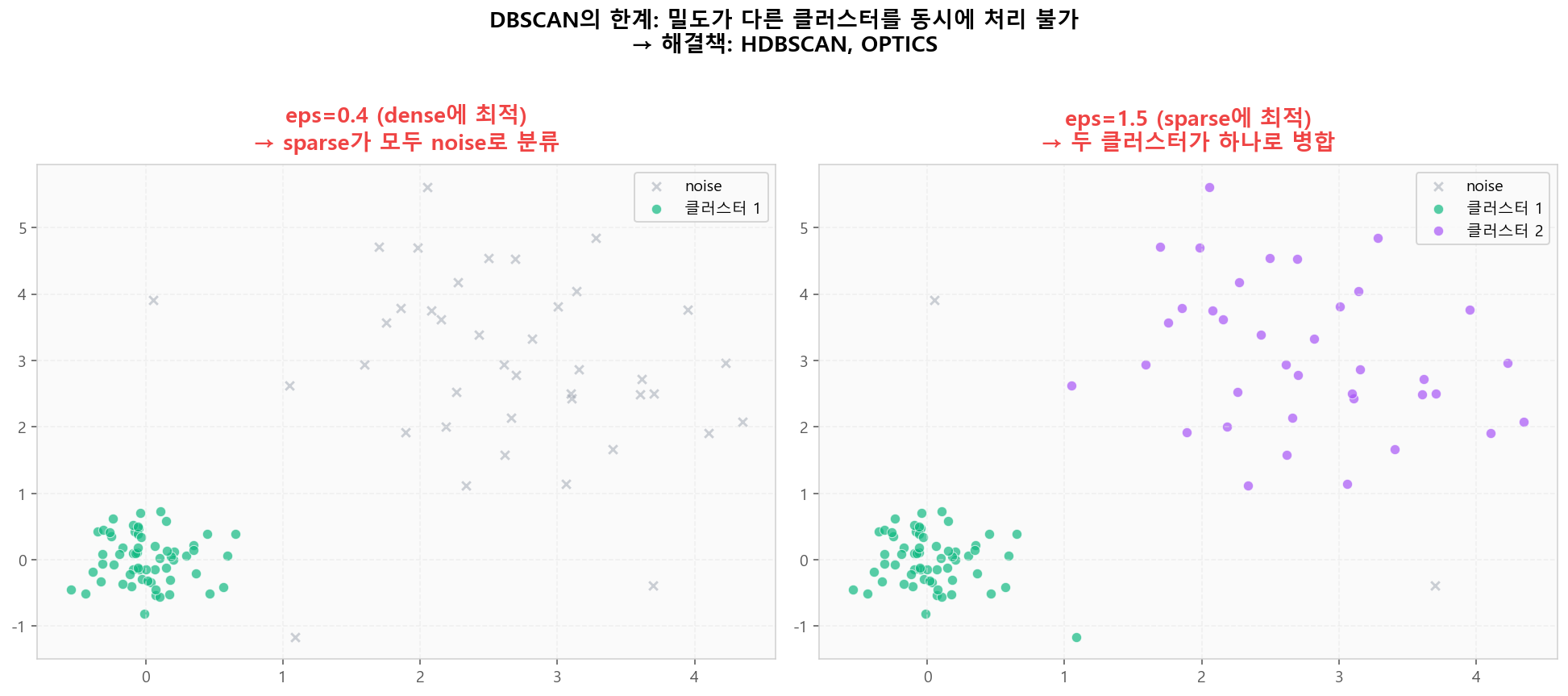 DBSCAN 한계: 밀도 격차 → HDBSCAN/OPTICS 필요
DBSCAN 한계: 밀도 격차 → HDBSCAN/OPTICS 필요알고리즘 비교 — 언제 무엇을 쓸까?
K-means
구형·균등 밀도 클러스터. K를 사전에 알고 있을 때.
DBSCAN
임의 모양 + 노이즈가 있는 경우. K 모름. 균등 밀도.
HDBSCAN / OPTICS
밀도 격차 큰 데이터. 매개변수 자동 조정.
직접 해보기 — 실습 과제
- K-means 한계 체감: 초승달 데이터 + 적정 eps. 두 초승달이 깔끔히 분리되는 것을 확인 → K-means로는 절대 불가능
- eps 한 칸 차이의 위력: 동심원 데이터 + eps 0.20 → 0.30 → 0.50. 결과가 매번 완전히 달라짐
- 노이즈 탐지: '3 클러스터 + 노이즈'. 균일하게 흩어진 노이즈가 자동으로 회색 X로 분류됨
- 점 하나 클릭: 임의 점에 마우스 호버 → 그 점의 eps 반경 원이 표시됨. core/border 차이를 시각적으로 확인
- 밀도 격차의 함정: '밀도 격차' 데이터셋에서 어떤 eps를 써도 두 클러스터를 동시에 잘 잡지 못함 — HDBSCAN이 필요한 상황