
넘스탯
DATA ANALYTICS & INSIGHTS
확률에서 LLM까지 – 데이터 사이언스 전문 교육 플랫폼
군집을 나무처럼 쌓아 올리는 방법
이 페이지에서 배우고 나면
- 가까운 데이터끼리 단계적으로 병합되는 과정을 직접 볼 수 있습니다.
- 덴드로그램(나무 그림)을 읽고 어디서 자를지 판단할 수 있습니다.
- K를 미리 정하지 않아도 되는 이유와 그 장단점을 이해할 수 있습니다.
🔽 Agglomerative — Bottom-up 병합 과정
모든 점을 각자 클러스터로 시작해, 가장 가까운 두 클러스터를 반복적으로 병합합니다. 결국 모든 점이 하나의 클러스터로 모일 때까지 진행합니다 — 이 모든 병합 이력이 덴드로그램입니다.
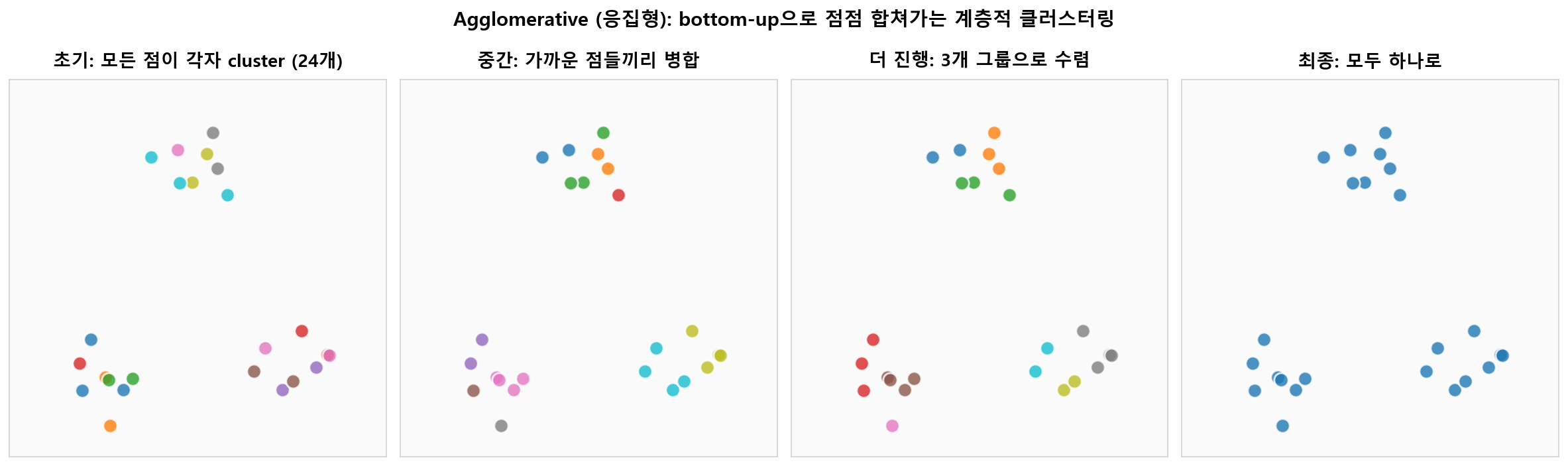 Agglomerative 클러스터링: bottom-up 단계별 병합
Agglomerative 클러스터링: bottom-up 단계별 병합덴드로그램 컷팅 — 클러스터 수 결정
덴드로그램에서 특정 높이에서 수평선을 그어 가로지르는 가지 수가 클러스터 수입니다. "가장 긴 수직 거리(jump)"가 있는 곳에서 자르는 것이 일반적인 휴리스틱입니다.
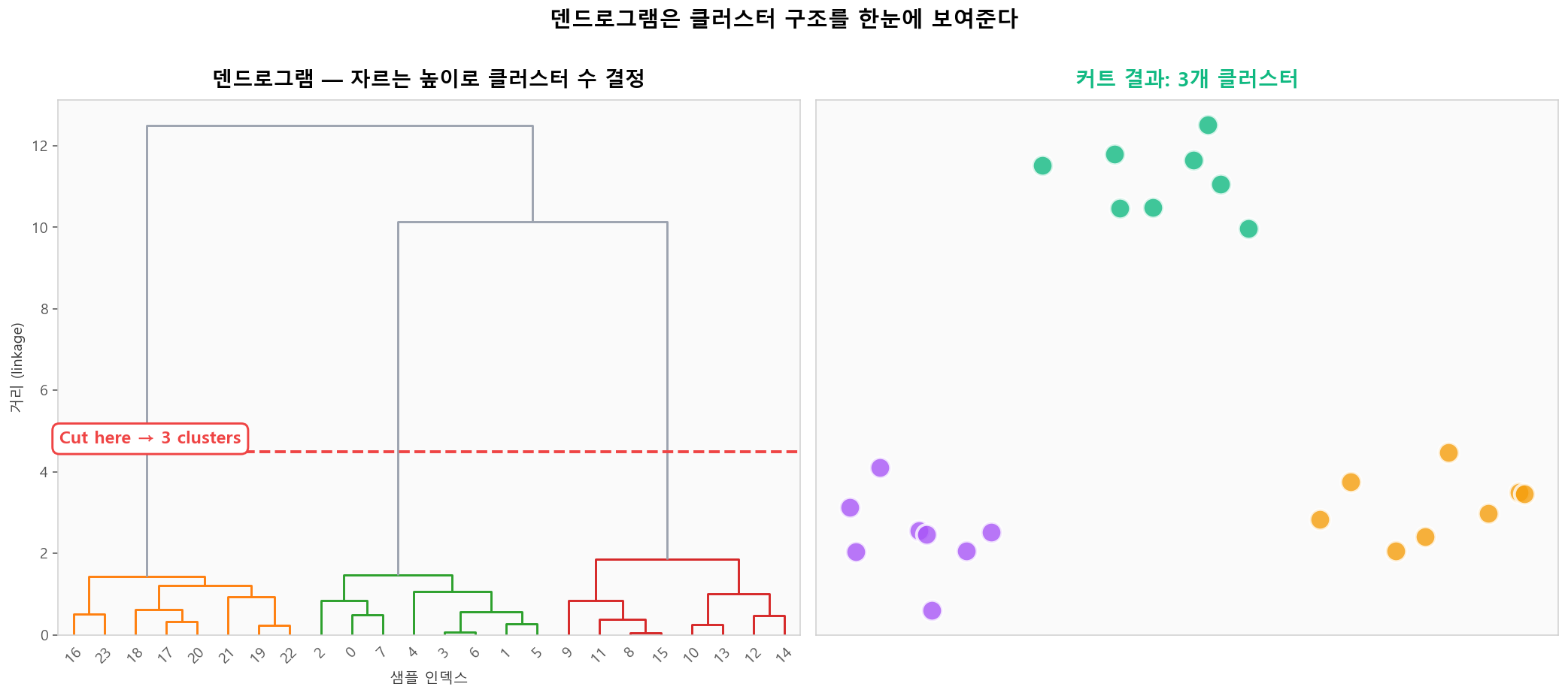 덴드로그램을 자르는 높이가 클러스터 수를 결정
덴드로그램을 자르는 높이가 클러스터 수를 결정계층적 클러스터링 인터랙티브 — Agglomerative + Dendrogram
Linkage 방식을 바꾸고 자르는 높이(클러스터 수)를 조정하며 결과 변화를 비교하세요.
Linkage 방식
클러스터 수 K = 3 (자르는 높이 ≈ 1.14)
클러스터링 결과 (산점도)
덴드로그램 (병합 트리)
Linkage 4종 — 거리 정의가 결과를 바꾼다
두 클러스터 사이의 거리를 어떻게 정의하느냐에 따라 결과가 달라집니다.Single(최단), Complete(최장), Average(평균), Ward(분산 증가량 최소) — 일반적으로 Ward가 가장 안정적입니다.
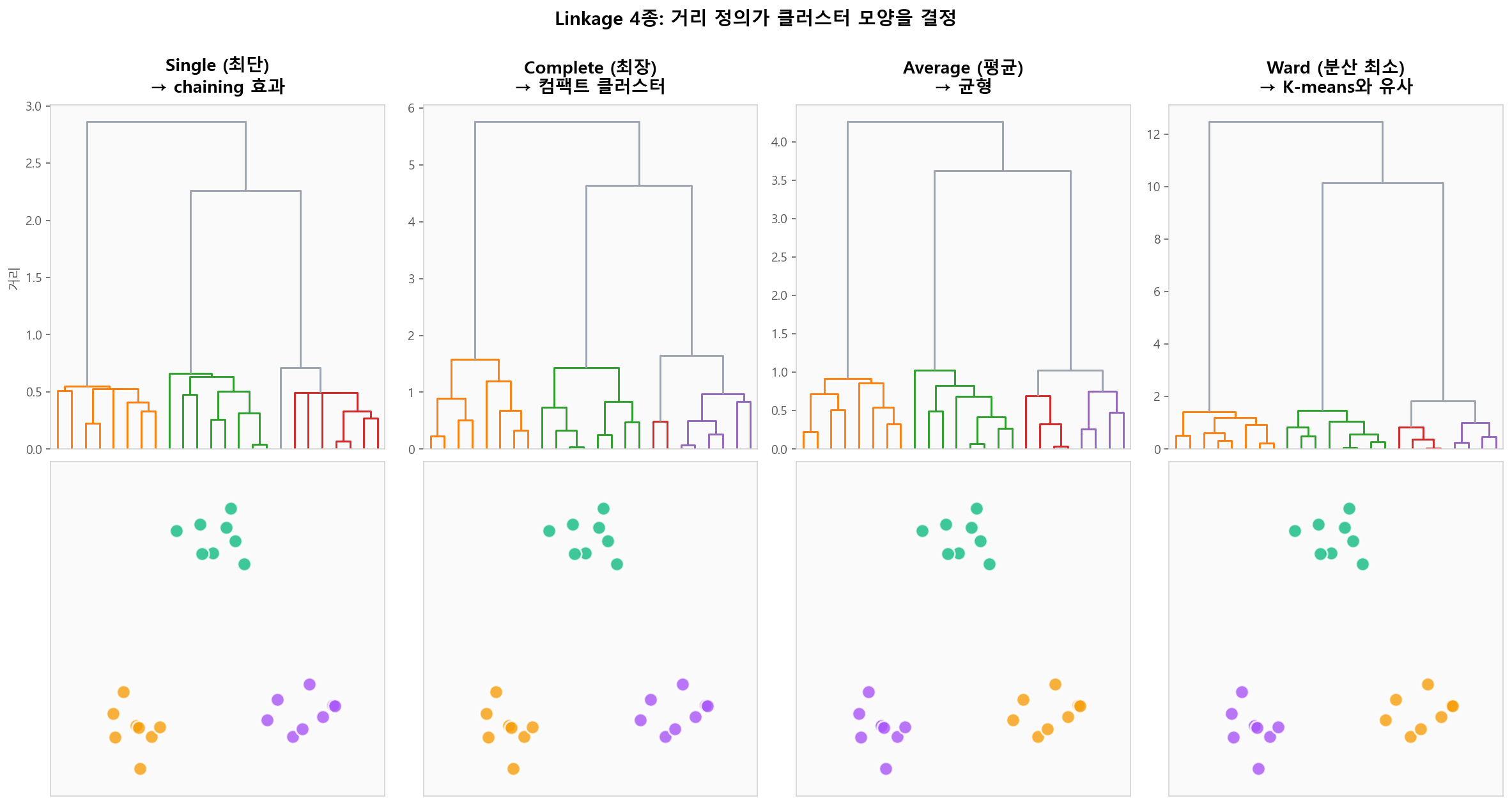 4종 linkage의 덴드로그램과 클러스터링 결과 비교
4종 linkage의 덴드로그램과 클러스터링 결과 비교거리 정의 시각화
각 linkage가 어떤 거리를 측정하는지 두 클러스터 A, B 예시로 확인합니다. Single은 한 쌍의 최단 거리, Complete는 최장 거리, Average는 모든 쌍의 평균, Ward는 병합 시 SSE 증가량을 최소화합니다.
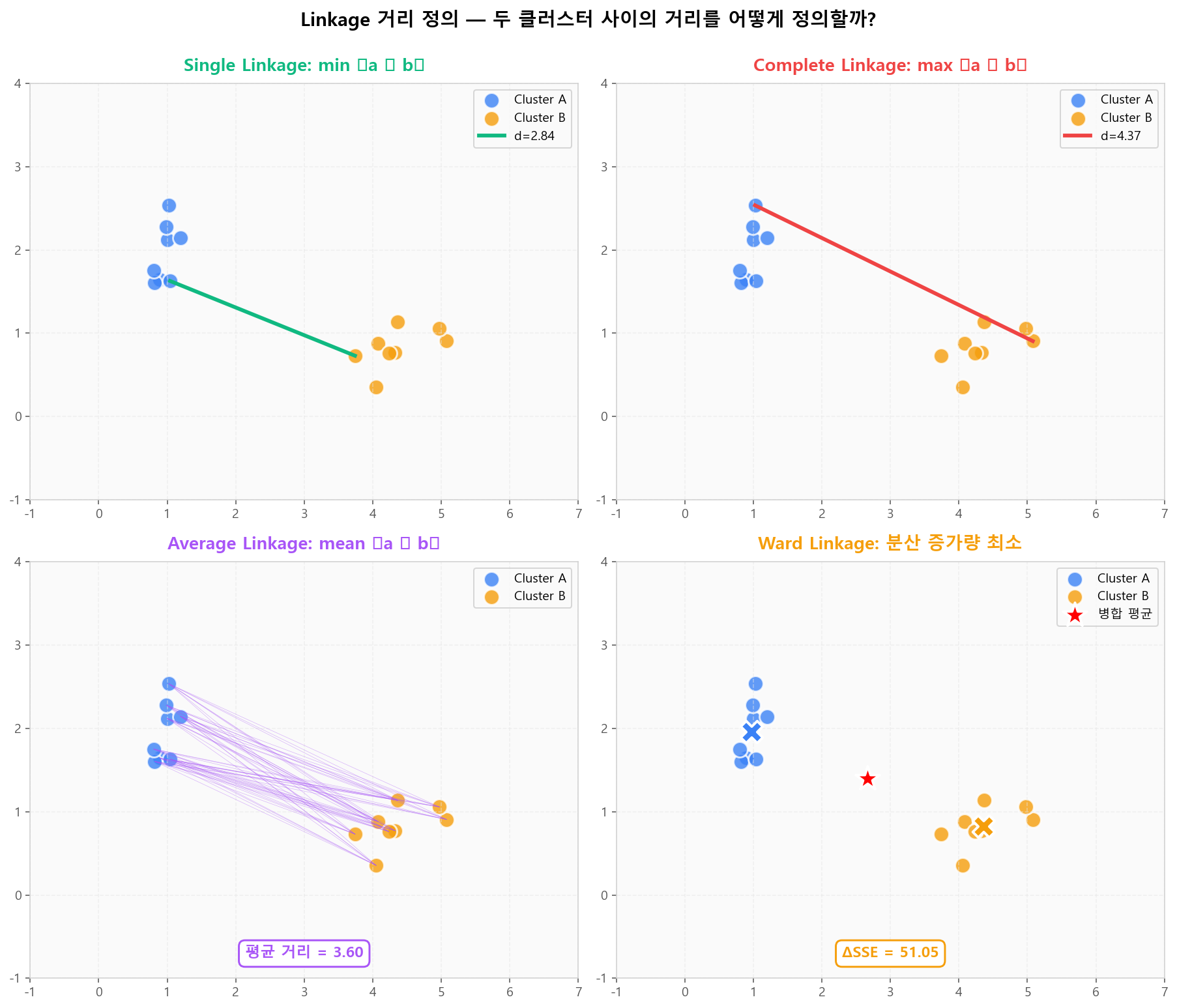 Linkage별 두 클러스터 간 거리 정의
Linkage별 두 클러스터 간 거리 정의🔀 Agglomerative vs Divisive
계층적 클러스터링은 두 방향이 가능합니다. Agglomerative(bottom-up)는 점→클러스터→하나로 합쳐가고, Divisive(top-down)는 하나에서 출발해 분할합니다. 실무는 거의 항상 Agglomerative를 사용합니다.
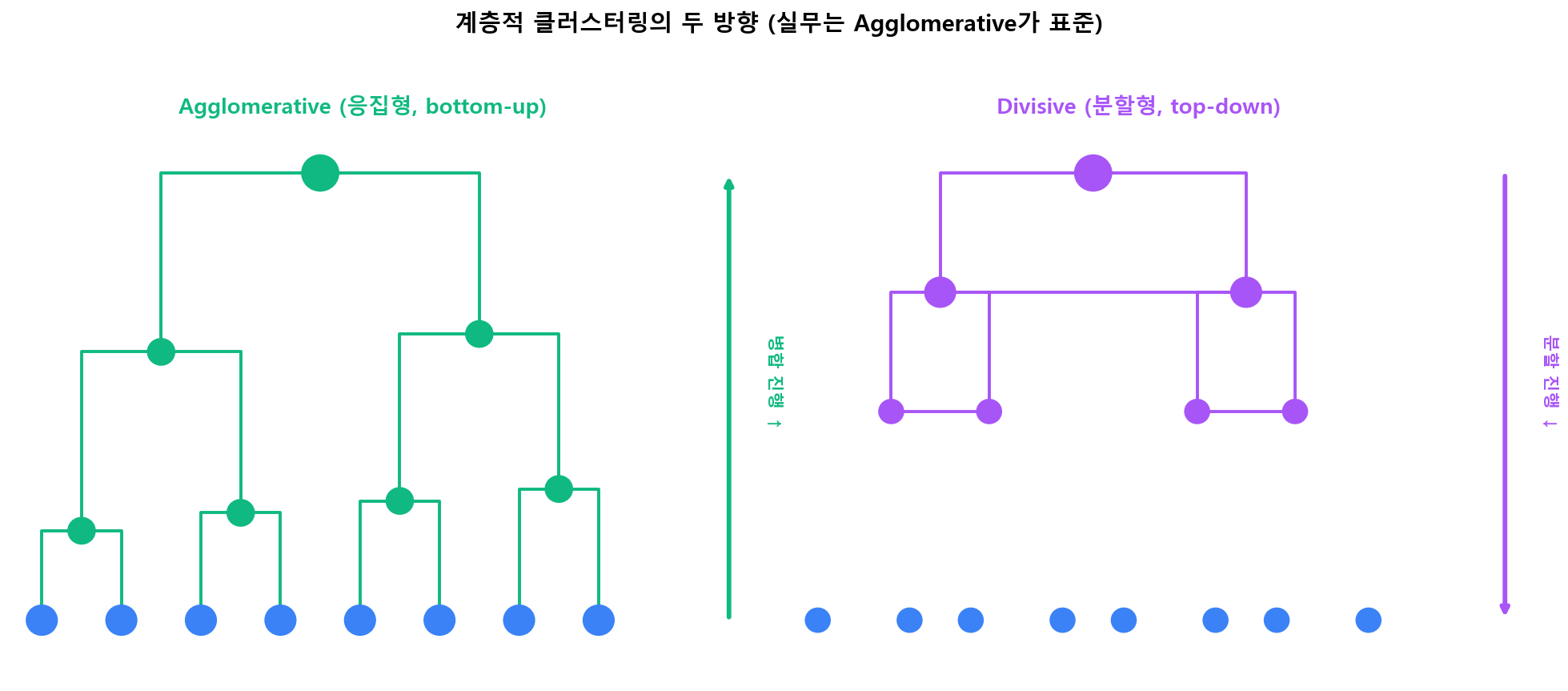 계층적 클러스터링의 두 방향 — Agglomerative가 표준
계층적 클러스터링의 두 방향 — Agglomerative가 표준언제 어떤 Linkage를 쓸까?
Single (최단)
Elongated/chain 모양 클러스터 탐지. 단점: chaining 효과로 노이즈에 약함.
Complete (최장)
컴팩트한 클러스터. 단점: outlier에 민감.
Average
Single과 Complete의 절충안. 노이즈에 비교적 강건.
Ward — 실무 기본값
분산 증가량을 최소화 → K-means와 유사한 컴팩트 균형 클러스터. scikit-learn 기본.
직접 해보기 — 실습 과제
- K 동적 조정: 슬라이더를 K=1→8로 옮기며 덴드로그램의 빨간 컷 라인이 위아래로 움직이는 것 관찰
- Linkage 비교: K=3 고정. Single → Complete → Average → Ward 순으로 바꿔보세요. Single은 elongated, Ward는 컴팩트한 형태
- 가장 긴 jump 찾기: 덴드로그램에서 수직선이 가장 긴 구간(jump가 큰 곳)이 자연스러운 컷 지점
- Single의 chaining: 점이 일렬로 나열된 데이터에서 Single은 모두 하나의 긴 클러스터로 잇기 쉬움