
넘스탯
DATA ANALYTICS & INSIGHTS
확률에서 LLM까지 – 데이터 사이언스 전문 교육 플랫폼
함께 팔리는 상품을, 데이터에서 찾아내기
이 페이지에서 배우고 나면
- 지지도·신뢰도·향상도가 각각 무엇을 재는지 직접 계산하며 이해할 수 있습니다.
- 자주 함께 등장하는 항목집합을 데이터에서 찾아낼 수 있습니다.
- 단순히 '함께 자주 나온다'는 것과 '의미 있는 관련'의 차이를 구분할 수 있습니다.
🧾 트랜잭션 데이터의 표현
연관 규칙의 입력은 거래(transaction) 목록입니다. 각 거래는 함께 구매된 아이템들의 집합이며, 이를 트랜잭션×아이템 매트릭스로 표현해 분석합니다.
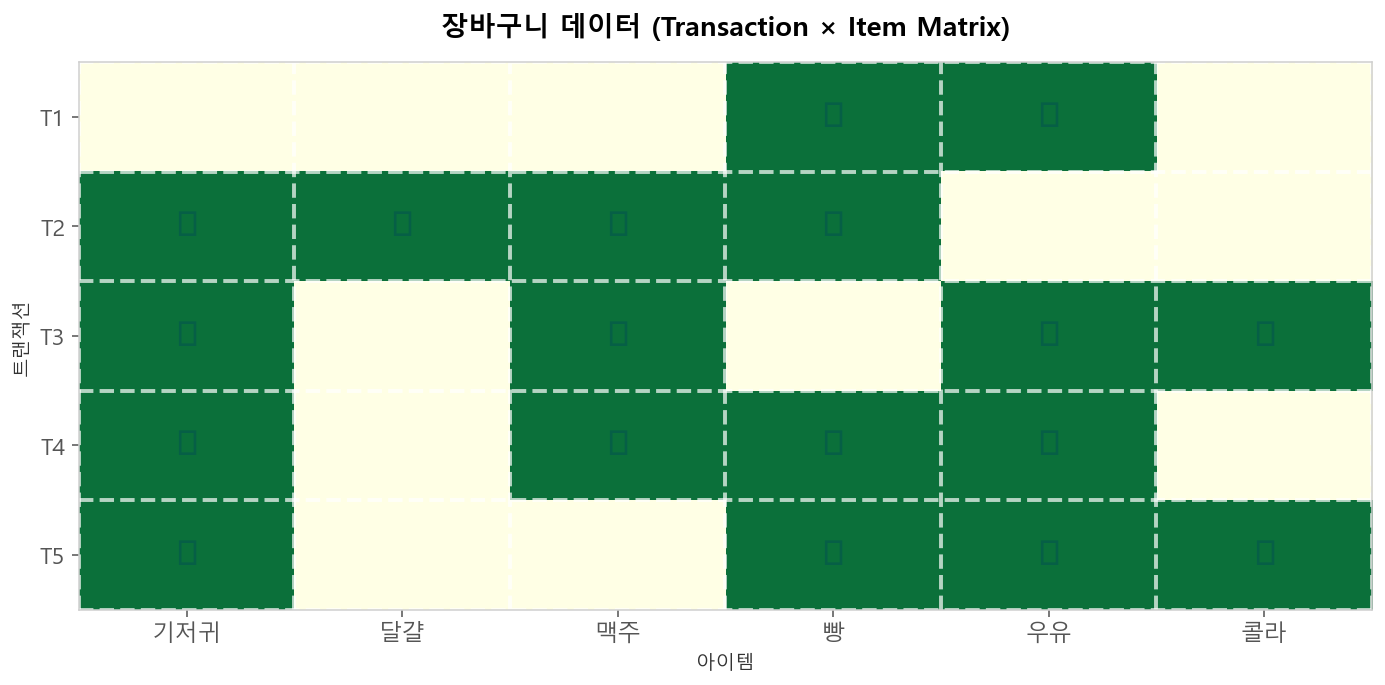 장바구니 데이터: Transaction × Item Matrix
장바구니 데이터: Transaction × Item Matrix3대 지표 — Support, Confidence, Lift
연관 규칙의 품질은 세 가지 지표로 평가합니다. Support는 빈도, Confidence는 조건부 확률 P(Y|X), Lift는 독립 가정 대비 몇 배 자주 발생하는가입니다. 실무에서 가장 중요한 것은 Lift로, 1.5 이상이면 의미 있는 규칙으로 봅니다.
 Support, Confidence, Lift의 정의와 예시 계산
Support, Confidence, Lift의 정의와 예시 계산🌳 Apriori 알고리즘 — Lattice와 가지치기
Apriori의 핵심 통찰: "비빈출 아이템셋의 모든 상위 집합도 비빈출"이라는 단조성(monotonicity) 성질입니다. 이를 활용해 가지치기(pruning)하면 2ⁿ개 후보를 거의 다 검사하지 않아도 됩니다.
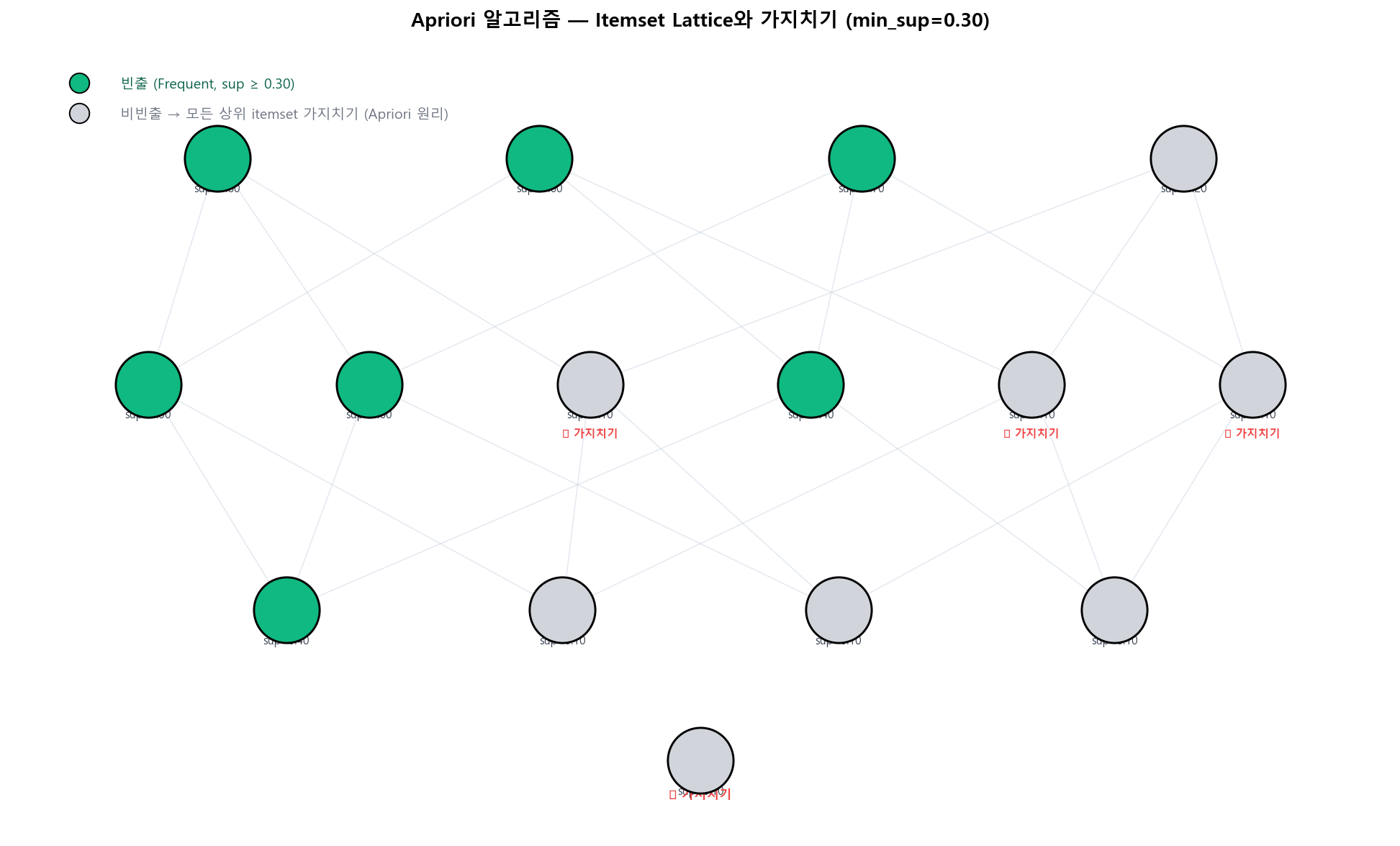 Apriori의 lattice 가지치기 — 4개 아이템 예시
Apriori의 lattice 가지치기 — 4개 아이템 예시연관 규칙(Apriori) 인터랙티브 — 장바구니 분석
미니 트랜잭션 데이터에서 Apriori 알고리즘으로 빈출 아이템셋과 연관 규칙을 발견합니다. min_support와 min_confidence를 조절해 발견되는 규칙의 변화를 관찰하세요.
데이터셋
min_support = 0.20 (4 트랜잭션 이상)
min_confidence = 0.50
빈출 아이템 (1-itemset)
| 아이템 | Support |
|---|---|
| 우유 | 0.70 |
| 빵 | 0.60 |
| 기저귀 | 0.55 |
| 맥주 | 0.55 |
| 버터 | 0.25 |
| 치즈 | 0.25 |
| 달걀 | 0.20 |
| 콜라 | 0.20 |
발견된 연관 규칙 (Lift 내림차순, 상위 10개)
| 규칙 (X → Y) | Support | Confidence | Lift |
|---|---|---|---|
기저귀 → 맥주 | 0.55 | 1.00 | 1.82 |
맥주 → 기저귀 | 0.55 | 1.00 | 1.82 |
기저귀, 빵 → 맥주 | 0.25 | 1.00 | 1.82 |
맥주, 빵 → 기저귀 | 0.25 | 1.00 | 1.82 |
기저귀, 우유 → 맥주 | 0.25 | 1.00 | 1.82 |
맥주, 우유 → 기저귀 | 0.25 | 1.00 | 1.82 |
버터 → 빵, 우유 | 0.20 | 0.80 | 1.78 |
버터 → 우유 | 0.25 | 1.00 | 1.43 |
버터, 빵 → 우유 | 0.20 | 1.00 | 1.43 |
버터 → 빵 | 0.20 | 0.80 | 1.33 |
Lift 히트맵 — 페어별 연관도
모든 아이템 페어의 Lift를 히트맵으로 시각화하면 강한 연관 페어를 한눈에 발견할 수 있습니다. 유명한 "기저귀 → 맥주" 사례(월마트, 1990년대)는 데이터마이닝의 고전적 발견입니다.
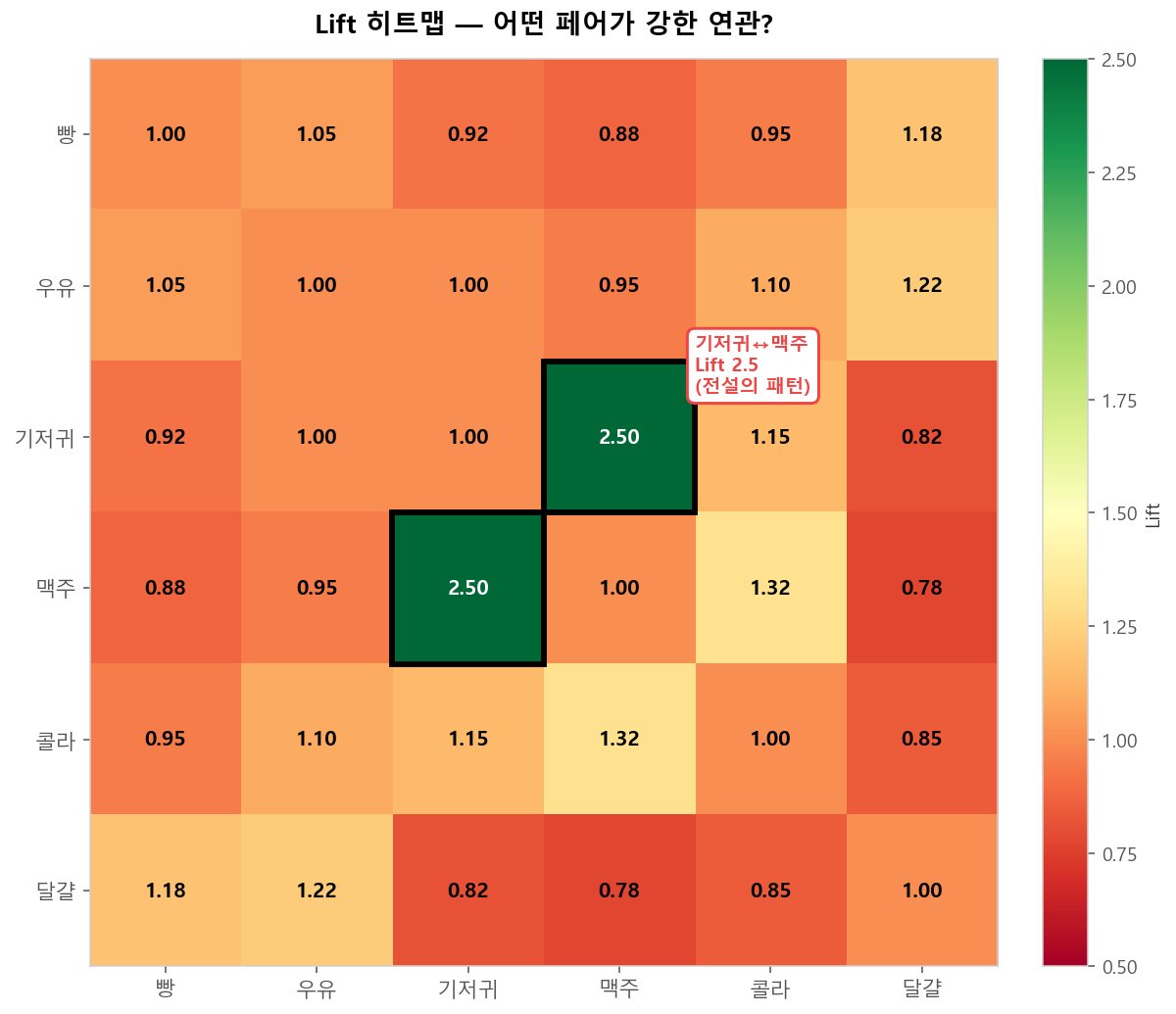 Lift 히트맵 — 빨강(음 상관) ↔ 녹색(양 상관)
Lift 히트맵 — 빨강(음 상관) ↔ 녹색(양 상관)💼 실제 응용 — 추천 시스템과 마케팅
연관 규칙은 추천 시스템·교차 판매(cross-selling)·매장 진열·번들 프로모션 등 광범위하게 활용됩니다. 현재 우리가 보는 아마존의 "함께 구매한 상품", 넷플릭스의 추천도 기본은 이 알고리즘의 변형입니다.
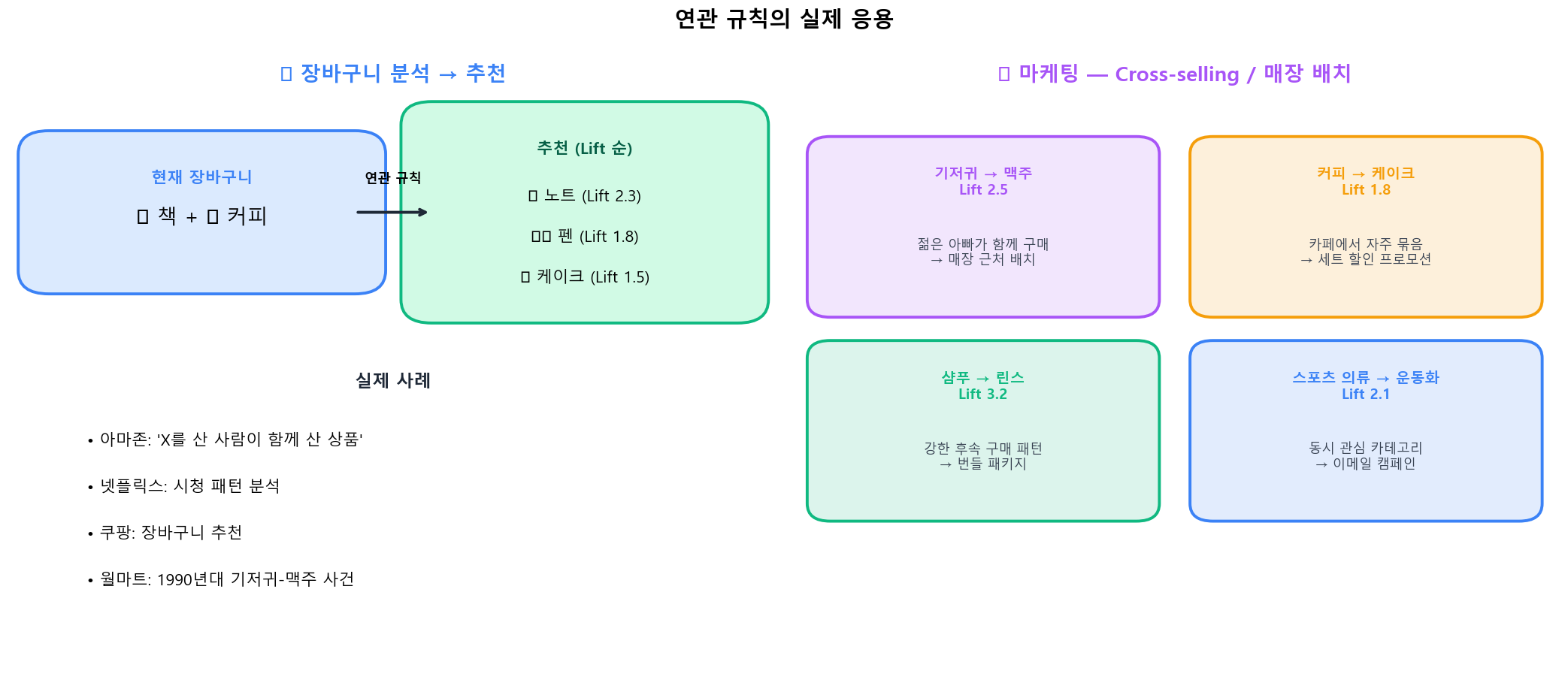 연관 규칙의 추천·마케팅 활용
연관 규칙의 추천·마케팅 활용Apriori vs FP-Growth vs Eclat
Apriori (1993)
레벨별 후보 생성 → DB 다회 스캔. 직관적이지만 느림.
FP-Growth (2000)
FP-tree 구조로 DB 2회 스캔만. Apriori 대비 10~100배 빠름.
Eclat (2000)
수직 데이터 표현 + 교집합으로 빠른 탐색. 메모리 효율.
직접 해보기 — 실습 과제
- 월마트 사례 재현: 식료품점 + min_sup=0.20 + min_conf=0.50. "기저귀 → 맥주", "맥주 → 기저귀" 규칙을 찾아보세요.
- support 효과: min_sup을 0.40 → 0.10으로 천천히 낮추세요. 규칙 수가 폭증하지만 그 중 의미 있는 것은 일부.
- confidence vs lift: confidence는 높지만 lift가 낮은 규칙은 "정답 Y가 그냥 많이 팔리는 것"일 수 있음. Lift 1.5 이상이 진짜 가치 있는 규칙.
- 의류 매장 분석: 데이터셋을 의류로 변경. "셔츠 → 청바지", "드레스 → 가방" 같은 코디 패턴이 자동 발견됨.
- 실무 적용 사고 실험: 발견된 Top 3 규칙으로 어떤 마케팅 액션(번들·진열·추천)을 할 수 있을지 직접 정리해보세요.