
넘스탯
DATA ANALYTICS & INSIGHTS
확률에서 LLM까지 – 데이터 사이언스 전문 교육 플랫폼
이상치 탐지 실습실
"이상치 탐지로 사기 잡고" — Isolation Forest, LOF, One-Class SVM 비교
원하는 개념·랩·가이드를 검색해보세요
Ctrl K정상이 무엇인지 배우면, 이상은 저절로 드러난다
이 페이지에서 배우고 나면
- 정상 패턴을 학습해 벗어난 점을 찾아내는 원리를 직접 관찰할 수 있습니다.
- 임계값을 바꾸면 정상/이상 판정이 어떻게 달라지는지 확인할 수 있습니다.
- 사기·고장 탐지처럼 이상 사례가 드문 문제에 왜 이 방식이 적합한지 이해할 수 있습니다.
이상치의 3가지 유형
Chandola et al. (2009)는 이상치를 세 가지로 분류합니다: (1) Point Anomaly — 단일 점이 비정상, (2) Contextual Anomaly — 맥락(시간·계절·지역)에 비정상, (3) Collective Anomaly — 점들의 모음이 비정상 패턴.
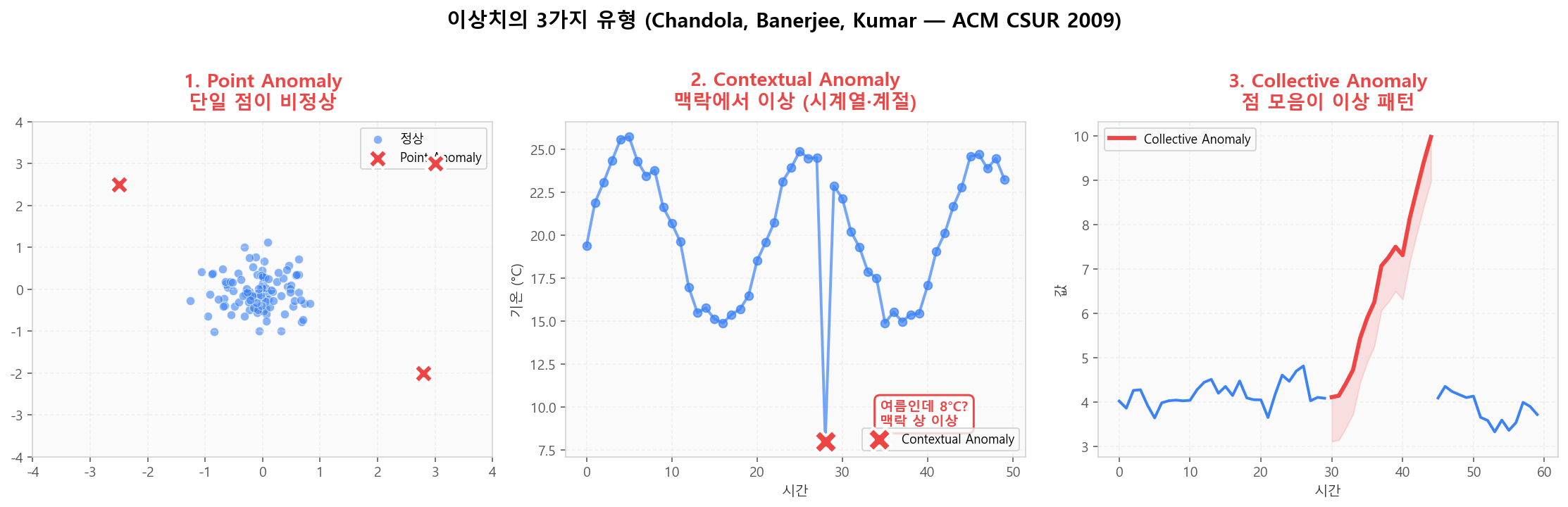 이상치의 3가지 유형 — Point / Contextual / Collective
이상치의 3가지 유형 — Point / Contextual / Collective🌲 Isolation Forest (Liu, Ting, Zhou — ICDM 2008)
Isolation Forest의 핵심 통찰: 이상치는 적은 무작위 분할로 격리된다. 즉, 무작위 split 트리에서 이상치의 path length가 짧고 정상점의 path length가 길다는 사실을 활용합니다. O(n) 시간으로 매우 빠르고 메모리 효율적입니다.
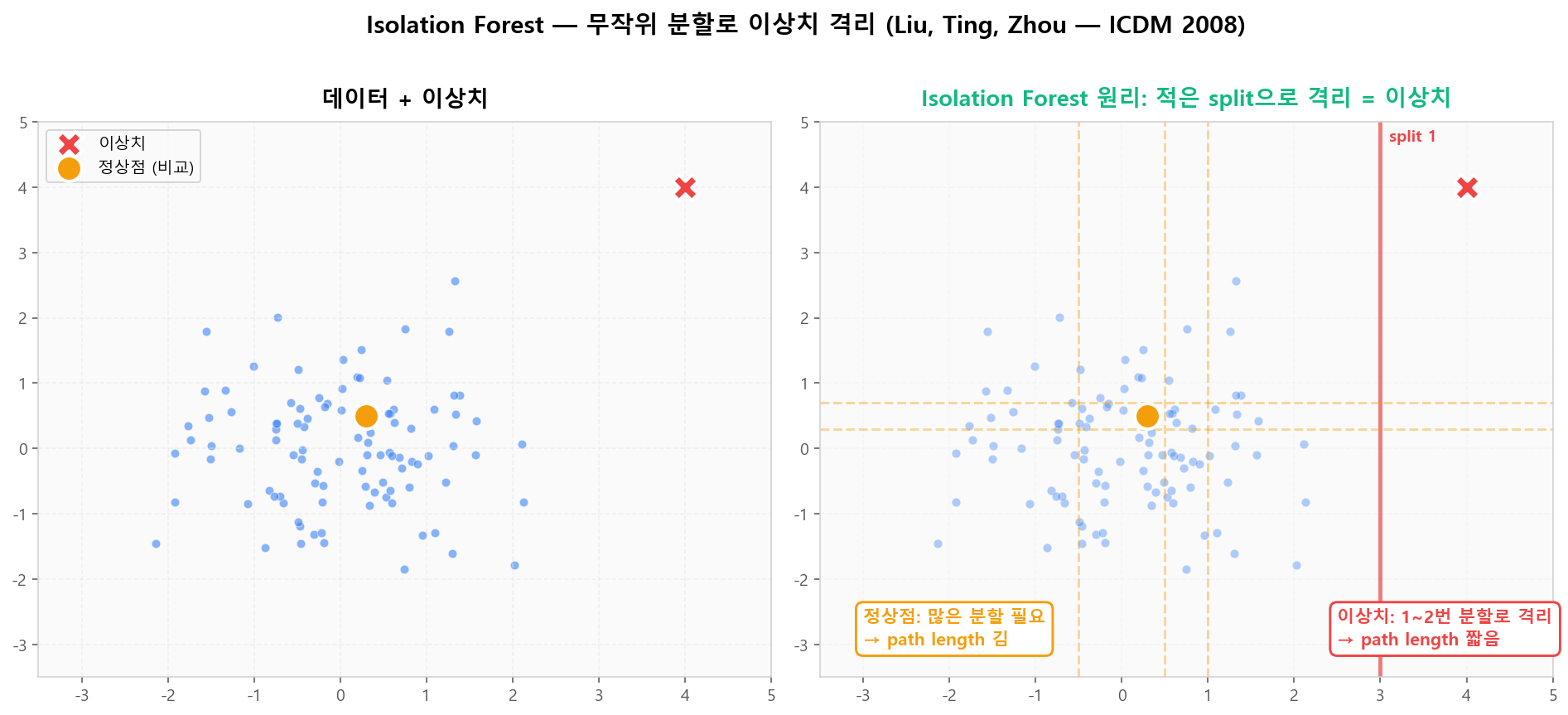 Isolation Forest — 무작위 분할로 이상치를 빠르게 격리
Isolation Forest — 무작위 분할로 이상치를 빠르게 격리📍 LOF — Local Outlier Factor (Breunig et al. — SIGMOD 2000)
LOF는 지역 밀도(local density)를 비교해 이상치를 탐지합니다. 점 p의 LOF는 "p의 이웃 밀도 / p의 이웃들이 갖는 이웃 밀도"의 비율로, 1보다 크게 벗어나면 이상치입니다. 밀도가 다른 군집이 공존하는 경우 전역 방법보다 우수합니다.
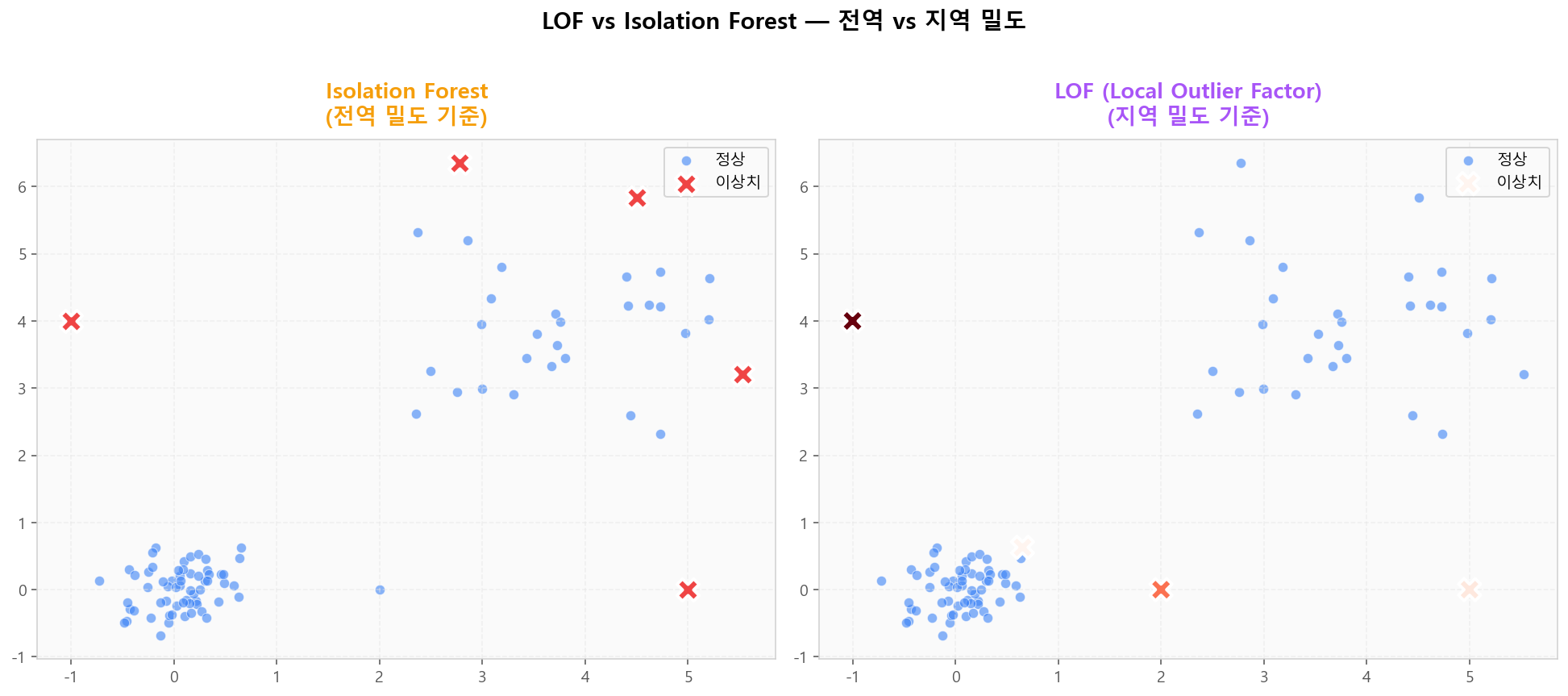 Isolation Forest (전역) vs LOF (지역) — 같은 데이터의 다른 판정
Isolation Forest (전역) vs LOF (지역) — 같은 데이터의 다른 판정One-Class SVM (Schölkopf et al. — NeurIPS 2000)
One-Class SVM은 정상 데이터만 학습해 정상 영역의 경계를 찾고, 경계 밖의 점을 이상치로 판정합니다. RBF 커널을 사용하면 임의의 비선형 정상 영역을 학습할 수 있습니다. 신용카드 사기처럼 정상 데이터만 풍부하고 이상치 라벨이 거의 없을 때 강력합니다.
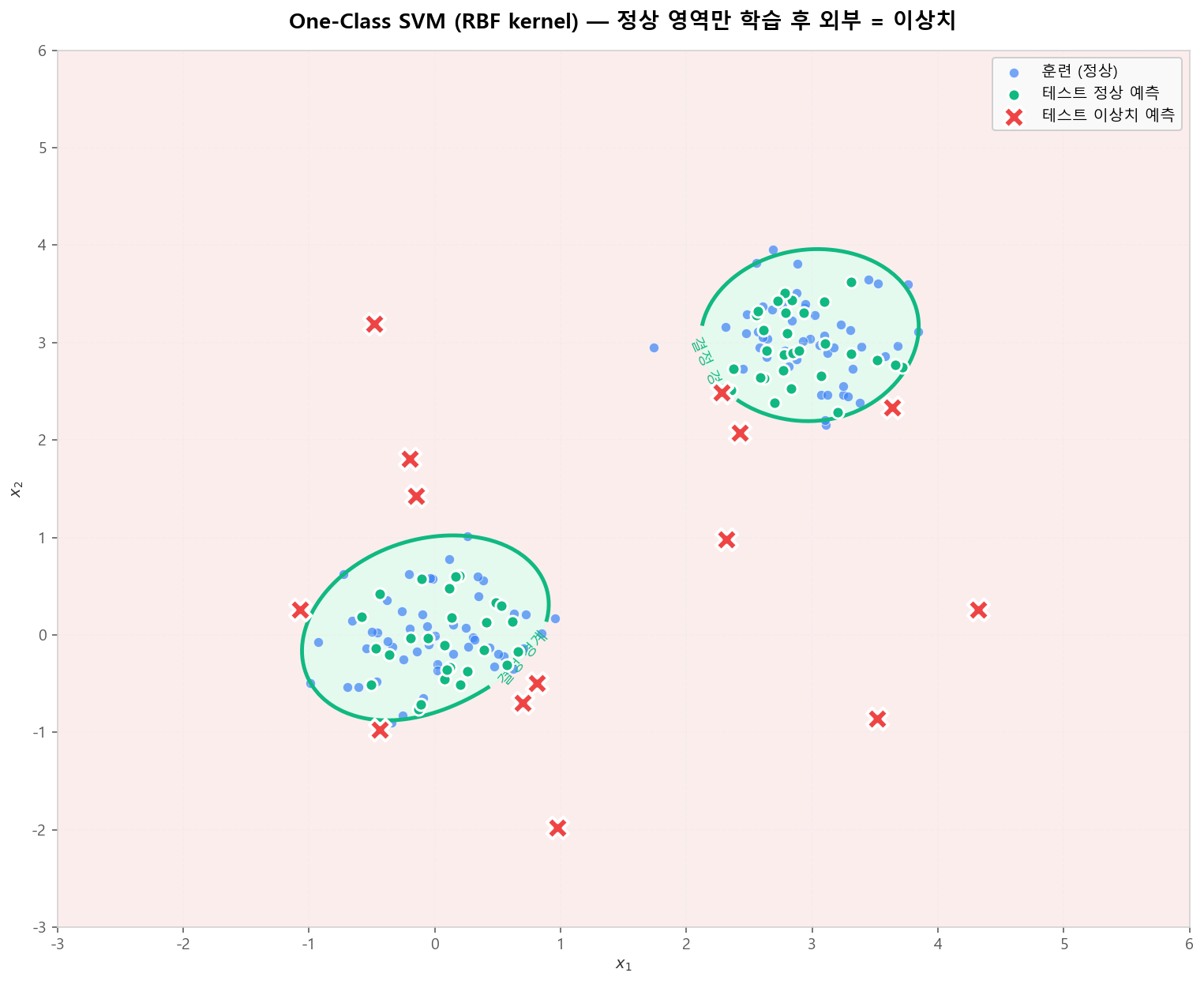 One-Class SVM (RBF) — 정상 영역의 경계 학습
One-Class SVM (RBF) — 정상 영역의 경계 학습이상치 탐지 인터랙티브 — 3가지 방법 비교
정상(파란색) + 이상치(빨간색) 데이터에 세 가지 방법을 적용해 정밀도·재현율·F1을 실시간 비교하세요.
탐지 방법
실제 이상치 비율 = 10%
Mahalanobis 임계값 = 2.5
χ²(2, 0.99) ≈ 3.03탐지 결과 시각화
혼동 행렬 (Confusion Matrix)
세 알고리즘 한눈에 비교
같은 데이터에 세 가지 알고리즘을 동시 적용한 결과입니다. 데이터 특성에 따라 최적 알고리즘이 달라집니다.
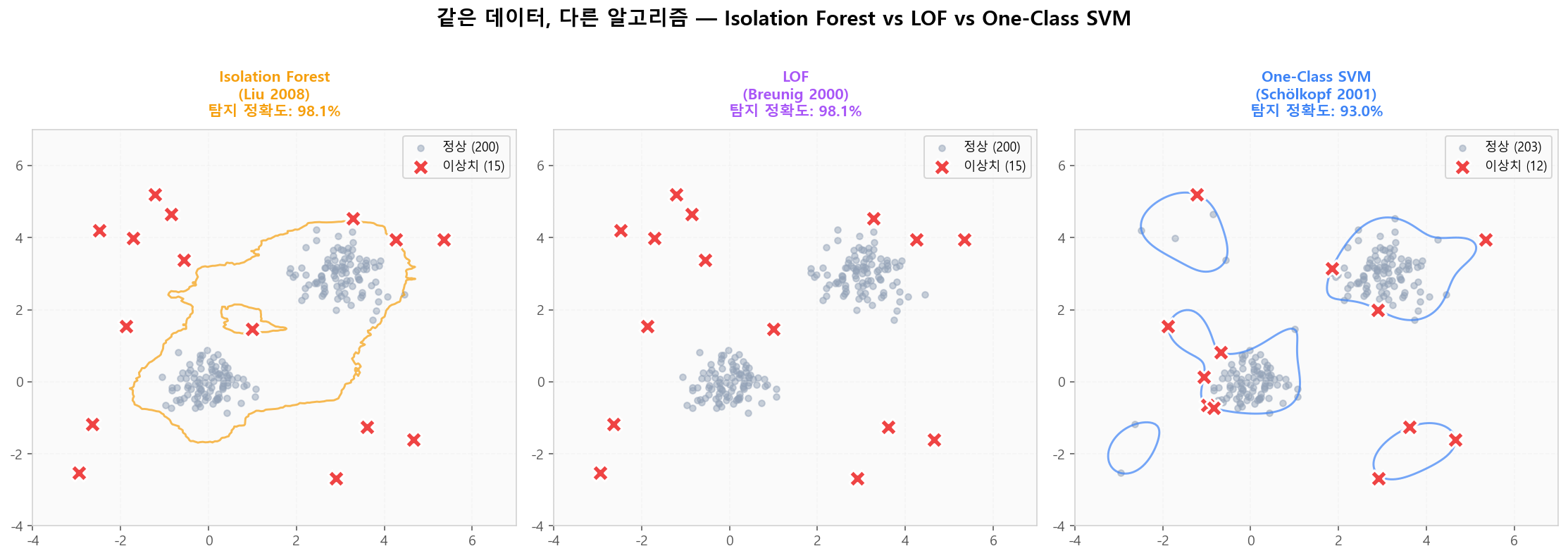 Isolation Forest vs LOF vs One-Class SVM — 동일 데이터, 다른 결정 경계
Isolation Forest vs LOF vs One-Class SVM — 동일 데이터, 다른 결정 경계알고리즘 선택 가이드
Isolation Forest — 기본값
대규모 데이터 (O(n)), 고차원 가능, 튜닝 적음. 가장 먼저 시도할 알고리즘.
LOF — 지역 밀도
밀도가 다른 군집 공존 시 우수. O(n²) 거리 계산으로 큰 데이터엔 부적합.
One-Class SVM
정상 라벨만 풍부할 때. RBF 커널로 비선형 정상 영역 학습. nu와 gamma 튜닝 필요.
Autoencoder (딥러닝)
정상 데이터를 잘 재구성하도록 학습 → 재구성 오차 큰 점이 이상치. 이미지·시계열에 강력.
💼 실제 응용 사례
💳 금융 사기 탐지
신용카드 거래 패턴(시간·금액·지역) 학습 → 비정상 거래 즉시 차단. PayPal, Stripe, 비자가 핵심 인프라로 사용.
🏭 제조 공정 불량 탐지
센서 데이터(온도·진동·전류) 학습 → 비정상 패턴 감지로 사전 정비. 삼성·LG·현대차 스마트팩토리 핵심.
🏥 의료 진단
정상 영상 학습 → 종양·병변 자동 탐지. CT·MRI·병리 영상 보조 진단에서 활용.
🔒 사이버 보안
네트워크 트래픽 패턴 학습 → DDoS, 침입, 멀웨어 자동 탐지. SIEM 솔루션의 핵심 기능.
직접 해보기 — 실습 과제
- 방법 비교: 같은 데이터에 Z-Score → Mahalanobis → k-NN을 순서대로 적용. F1 점수 비교
- 임계값 효과: Z-Score 임계값을 1.5 → 3.5로 올리면 Recall↓ Precision↑. 사기 탐지에서는 어느 쪽 우선?
- 이상치 비율의 함정: outlier ratio를 30%로 올리면 통계 방법(Z, Mahalanobis)의 평균·분산이 오염되어 성능 저하 — 강건 통계 필요
- k-NN의 k 효과: k=3 (지역적, 노이즈에 민감) vs k=20 (부드러움). 데이터 크기와 잡음에 따라 조정
- Precision vs Recall 선택: 사기 탐지(놓치면 손해 큼) → Recall 우선 / 알람 피로(스팸 같은 환경) → Precision 우선
📖 더 깊이 학습하기
- Chandola, Banerjee, Kumar (ACM Computing Surveys 2009): "Anomaly Detection: A Survey" — 종합 서베이
- Liu, Ting, Zhou (ICDM 2008): "Isolation Forest" — IF 원논문
- Breunig, Kriegel, Ng, Sander (SIGMOD 2000): "LOF: Identifying Density-Based Local Outliers" — LOF 원논문
- Schölkopf et al. (NeurIPS 2000): "Support Vector Method for Novelty Detection" — One-Class SVM
- scikit-learn 문서: IsolationForest, LocalOutlierFactor, OneClassSVM
- PyOD (Python Outlier Detection): 가장 종합적인 이상치 탐지 라이브러리