
넘스탯
DATA ANALYTICS & INSIGHTS
확률에서 LLM까지 – 데이터 사이언스 전문 교육 플랫폼
정규화 실습실
L1/L2·Dropout·Early Stopping — 과적합을 막고 일반화를 끌어올리는 4가지 도구
원하는 개념·랩·가이드를 검색해보세요
Ctrl K시험을 잘 보는 학생 vs 답을 통째로 외운 학생
이 페이지에서 배우고 나면
- 과적합이 학습·검증 곡선에서 어떻게 드러나는지 직접 볼 수 있습니다.
- 드롭아웃·L2 등 정규화가 모델을 어떻게 단순하게 만드는지 이해할 수 있습니다.
- 훈련 정확도가 높다고 좋은 모델이 아니라는 점을 실험으로 확인할 수 있습니다.
Bias-Variance Tradeoff
모델이 단순하면 underfitting(편향 ↑), 너무 복잡하면 overfitting(분산 ↑). 검증 오차의 U자 곡선에서 최저점이 우리가 찾는 지점이며, 정규화가 그 균형을 잡아줍니다.
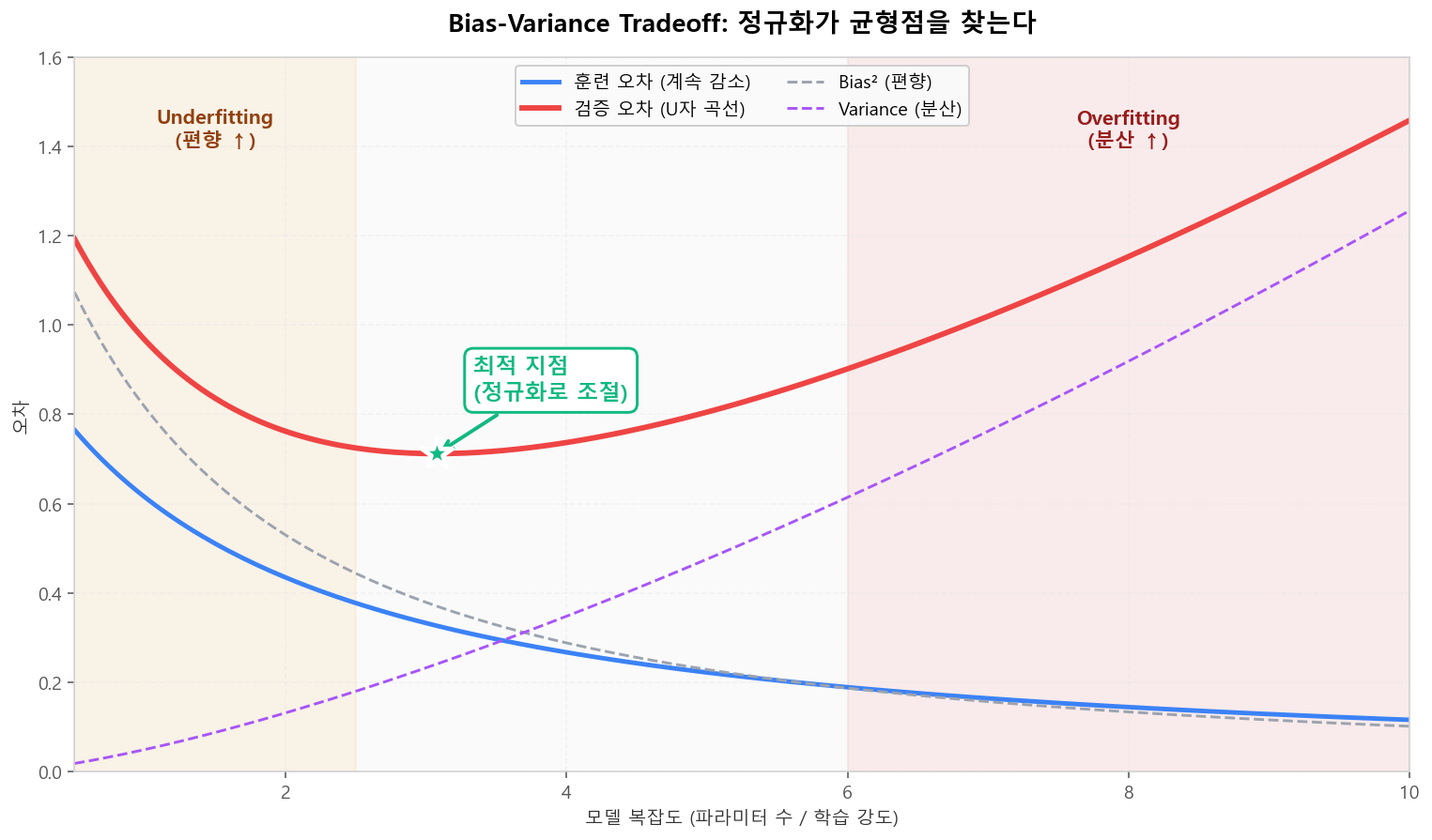 모델 복잡도와 일반화 오차의 U자 관계 — 정규화가 균형점을 찾는 도구
모델 복잡도와 일반화 오차의 U자 관계 — 정규화가 균형점을 찾는 도구📉 훈련 vs 검증 곡선
정규화가 없으면 훈련 손실은 계속 줄어도 검증 손실은 어느 순간 다시 오릅니다. 그 분기점에서 학습을 멈추는 것이 Early Stopping이고, 페널티를 추가해 그 분기를 늦추는 것이 L1/L2/Dropout입니다.
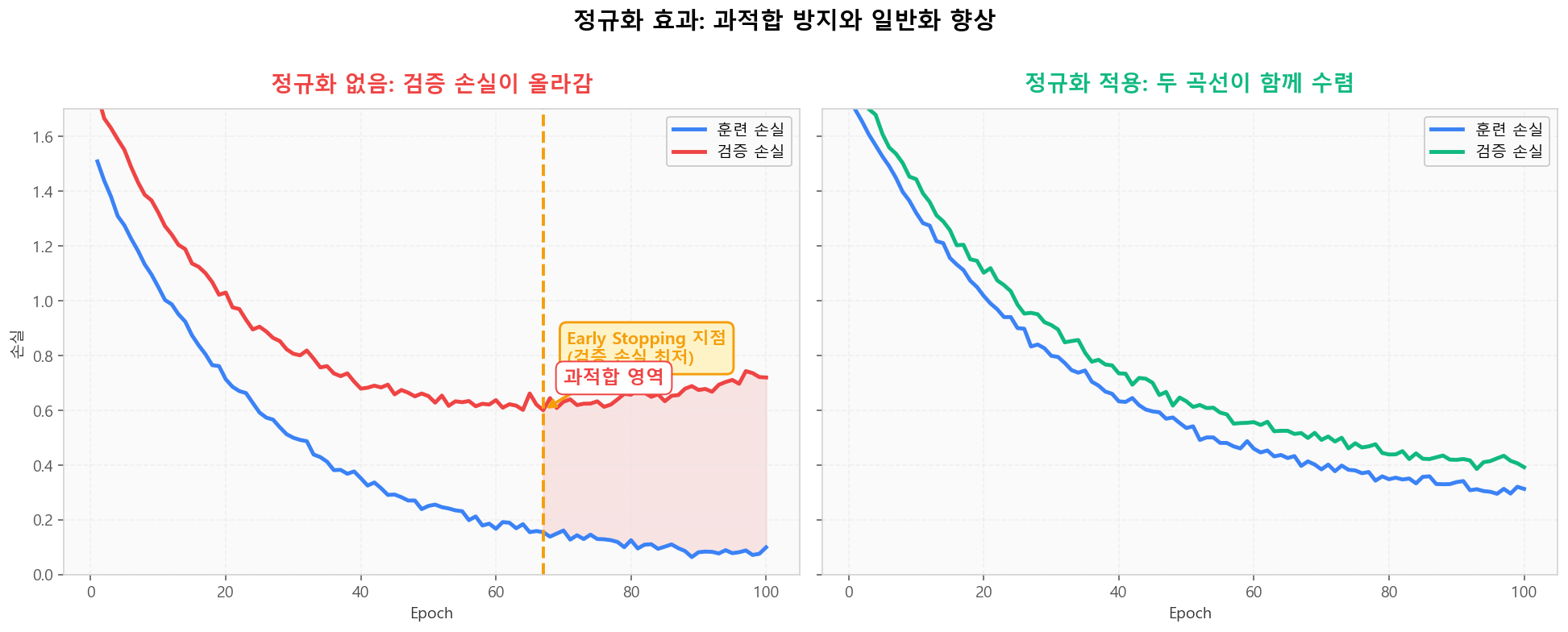 과적합 vs 정규화: 검증 곡선이 다르게 움직인다
과적합 vs 정규화: 검증 곡선이 다르게 움직인다정규화 인터랙티브 랩 — 다항 회귀 + L2 Ridge
모델 복잡도(차수)와 정규화 강도(λ)를 조정하며 과적합과 일반화의 균형을 직접 체감하세요.
다항 차수 (모델 복잡도) = 9
1~15: 차수가 클수록 과적합 위험 증가잡음 수준 = 0.25
데이터 잡음 크기 (잡음이 클수록 정규화 효과 ↑)정규화
λ (정규화 강도) = 10-6 = 1.00e-6
log scale: 1e-8(거의 없음) ~ 1e0(매우 강함)📐 L1 vs L2: 기하학적 차이
L1(다이아몬드)은 꼭짓점에서 손실 등고선과 만나 일부 가중치를 정확히 0으로 만듭니다(희소성). L2(원)는 매끄러운 표면에서 만나 모든 가중치를 작게 만들지만 0에는 도달하지 않습니다.
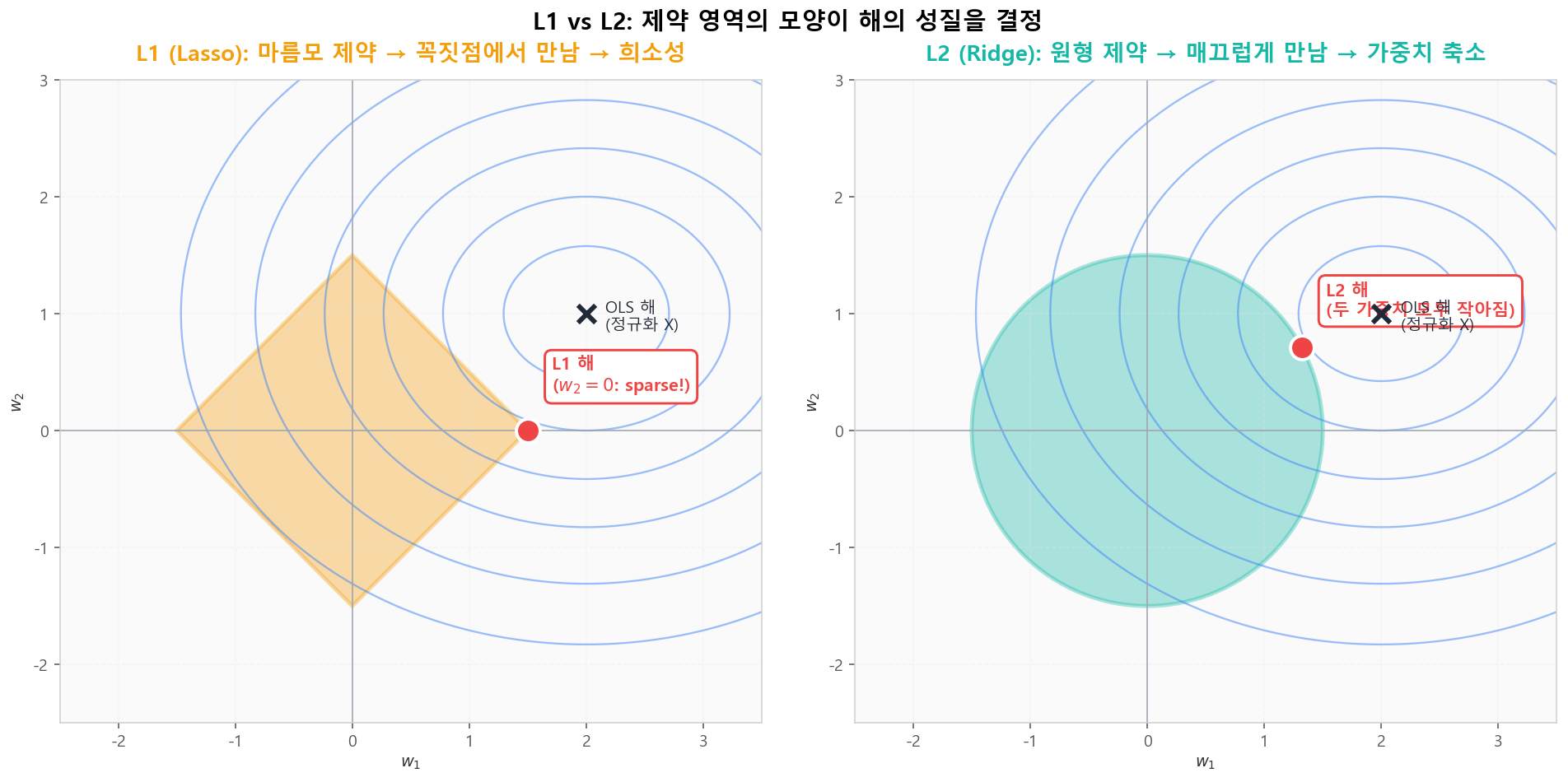 L1 다이아몬드 vs L2 원: 제약 영역의 모양이 해의 성질을 결정
L1 다이아몬드 vs L2 원: 제약 영역의 모양이 해의 성질을 결정정규화가 가중치 분포에 미치는 영향
학습된 가중치의 히스토그램을 비교해보면 정규화 효과가 한눈에 보입니다. L2는 가중치를 0 주변으로 모으고(축소), L1은 일부를 정확히 0으로 만듭니다(특징 선택).
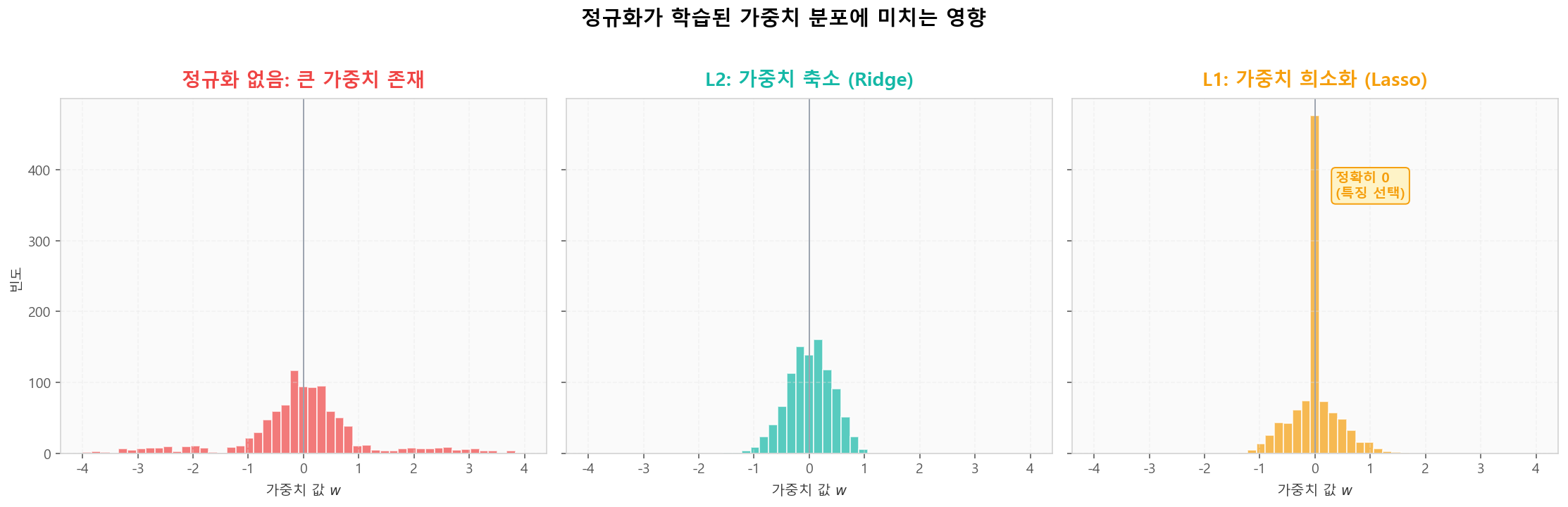 정규화별 학습된 가중치 분포 비교
정규화별 학습된 가중치 분포 비교Dropout: 자동 앙상블
학습 step마다 은닉 뉴런 일부를 무작위로 꺼서 매번 다른 "부분 네트워크"를 학습합니다. 100개 뉴런에서 50%를 끄면 가능한 부분 네트워크는 2¹⁰⁰개 — 자동으로 앙상블 효과를 얻습니다.
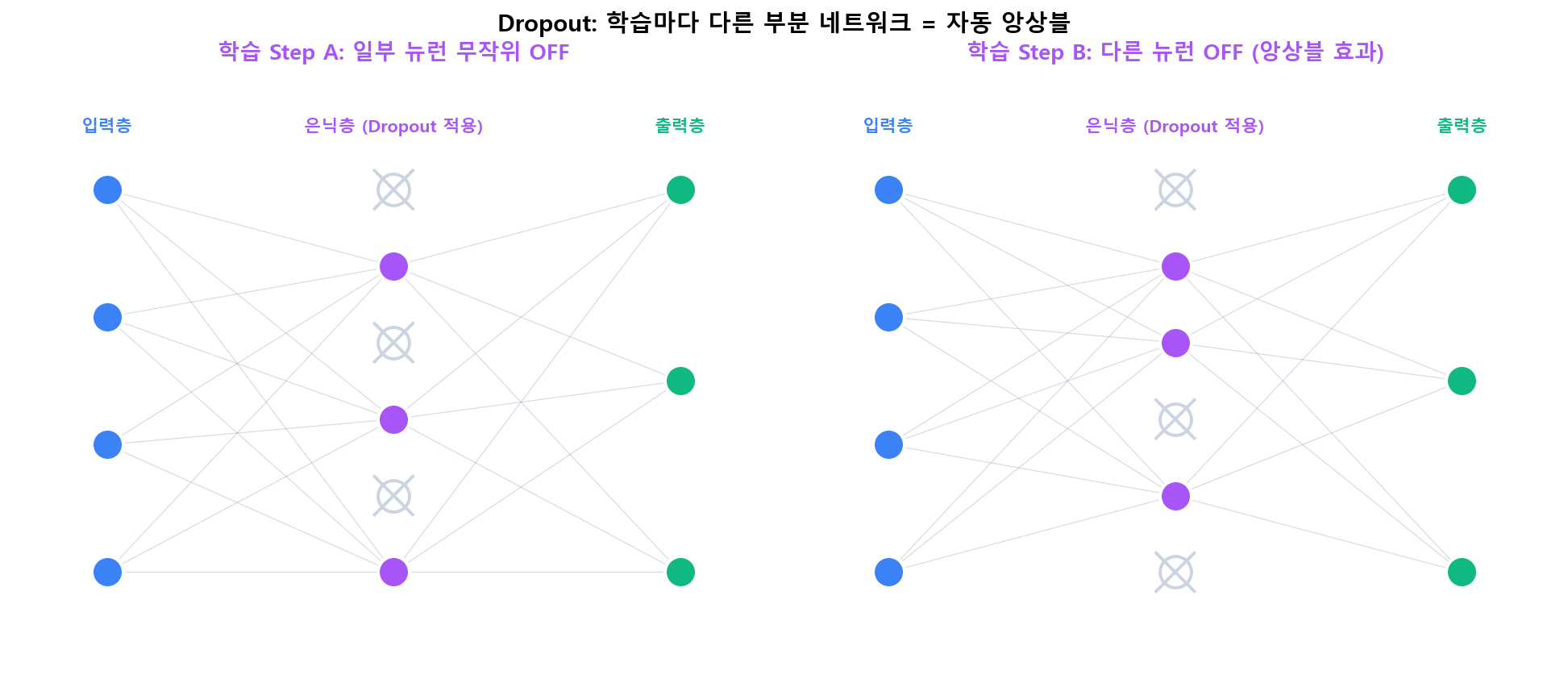 Dropout: 학습마다 다른 부분 네트워크를 사용 = 무료 앙상블
Dropout: 학습마다 다른 부분 네트워크를 사용 = 무료 앙상블정규화 기법별 사용 가이드
L2 (Ridge) — 가장 범용
거의 모든 딥러닝 모델의 기본. PyTorch weight_decay=1e-4가 표준. Adam에서는 AdamW(decoupled)를 써야 제대로 작동합니다.
L1 (Lasso) — 특징 선택
중요한 특징만 골라내고 나머지를 0으로 만듭니다. 해석 가능성이 중요한 도메인(의료, 금융)에서 유용.
Dropout — 자동 앙상블
Fully-connected 층에 p=0.2~0.5로 적용. BN과 함께 쓰면 효과가 줄어드는 경향.
Early Stopping — 가장 간단
검증 손실이 N epoch 연속 개선 안 되면 학습 중단. 하이퍼파라미터 거의 없고 효과 큼.
직접 해보기 — 실습 과제
- 과적합 만들기: 정규화 OFF + degree=15, 잡음 0.3. 곡선이 모든 점을 출렁이며 따라가는 것을 관찰. 검증 MSE가 폭증.
- L2로 안정화: L2 ON + λ=1e-3. 곡선이 부드러워지고 검증 MSE가 감소. 가중치 노름 ‖w‖도 함께 줄어듭니다.
- 스위트 스폿 찾기: λ를 1e-7부터 1e0까지 천천히 올리면서 검증 MSE 최저점을 찾으세요. 너무 크면 underfitting.
- 잡음과 정규화: 잡음을 0.5로 올리고 동일 λ로 학습. 잡음이 많을수록 정규화의 상대적 효과가 커집니다.
- 차수 vs λ의 균형: degree=3, λ=0 으로도 충분히 좋은 fit인지 확인. "모델을 줄이는 것"도 정규화의 한 형태입니다.