
넘스탯
DATA ANALYTICS & INSIGHTS
확률에서 LLM까지 – 데이터 사이언스 전문 교육 플랫폼
배치 정규화 실습실
깊은 신경망의 학습을 가능케 한 결정적 혁신 — Ioffe & Szegedy, 2015
원하는 개념·랩·가이드를 검색해보세요
Ctrl K층마다 값을 '표준화'하면 학습이 빨라진다
이 페이지에서 배우고 나면
- 배치 정규화가 각 층에서 무엇을 하는지 직접 관찰할 수 있습니다.
- 정규화가 학습 속도와 안정성에 주는 효과를 비교할 수 있습니다.
- 값의 분포가 층을 지나며 어떻게 변하는지 눈으로 확인할 수 있습니다.
내부 공변량 변화 (Internal Covariate Shift)
학습이 진행되면서 각 층의 입력 분포가 흔들립니다. 윗줄은 BN 없을 때 평균·분산이 점점 변하는 모습, 아랫줄은 BN 적용 시 분포가 매번 표준화되어 안정적인 모습입니다.
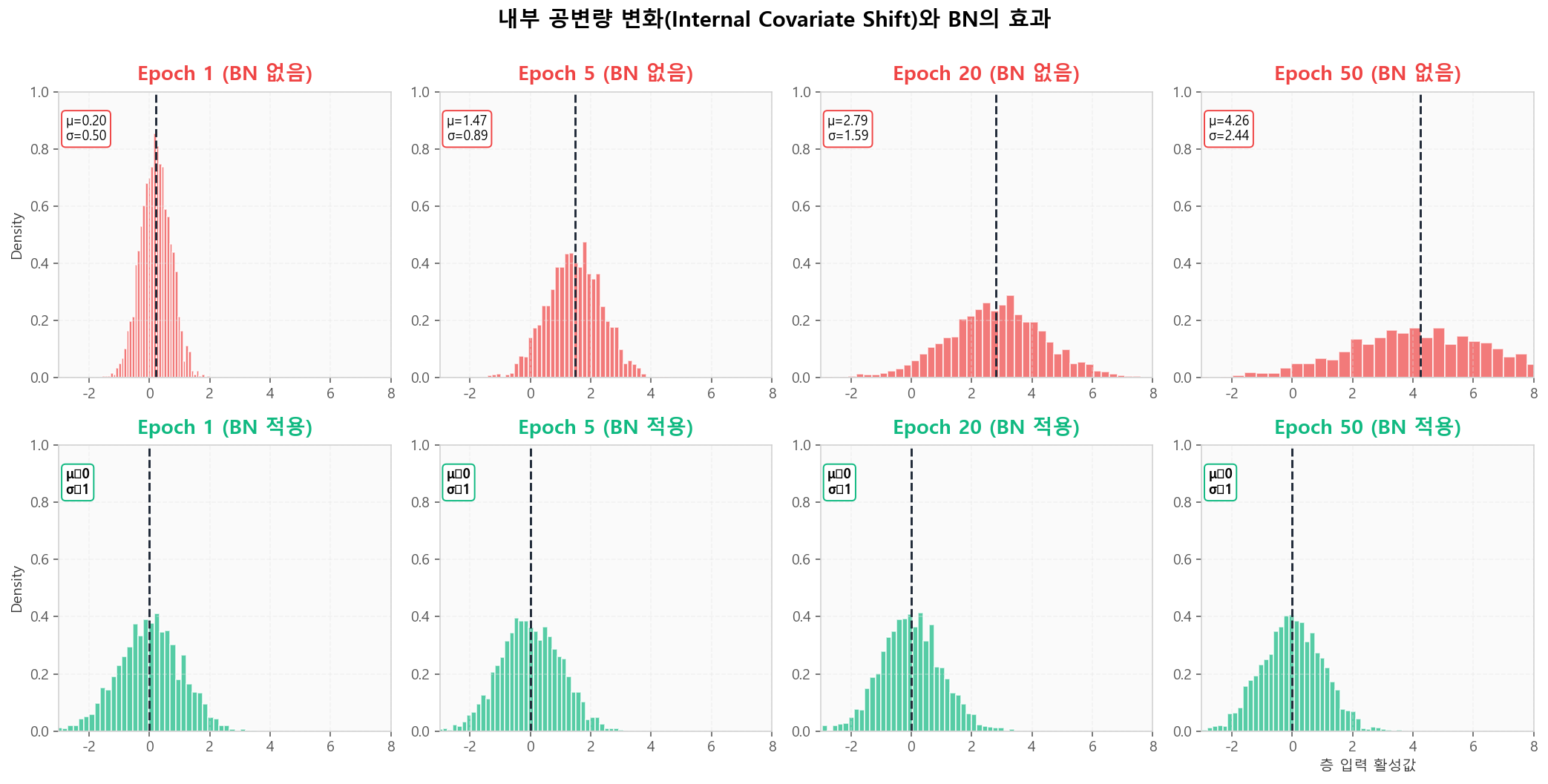 Internal Covariate Shift — BN 없으면 분포가 흐트러지지만 BN이 매번 표준화
Internal Covariate Shift — BN 없으면 분포가 흐트러지지만 BN이 매번 표준화🔧 BN 알고리즘 4단계
미니배치 입력 → 평균·분산 계산 → 정규화 → 학습 가능한 γ, β로 스케일·시프트. γ, β는 모델이 "정규화가 너무 강하다"고 판단하면 원래 분포를 복원할 수 있는 escape hatch입니다.
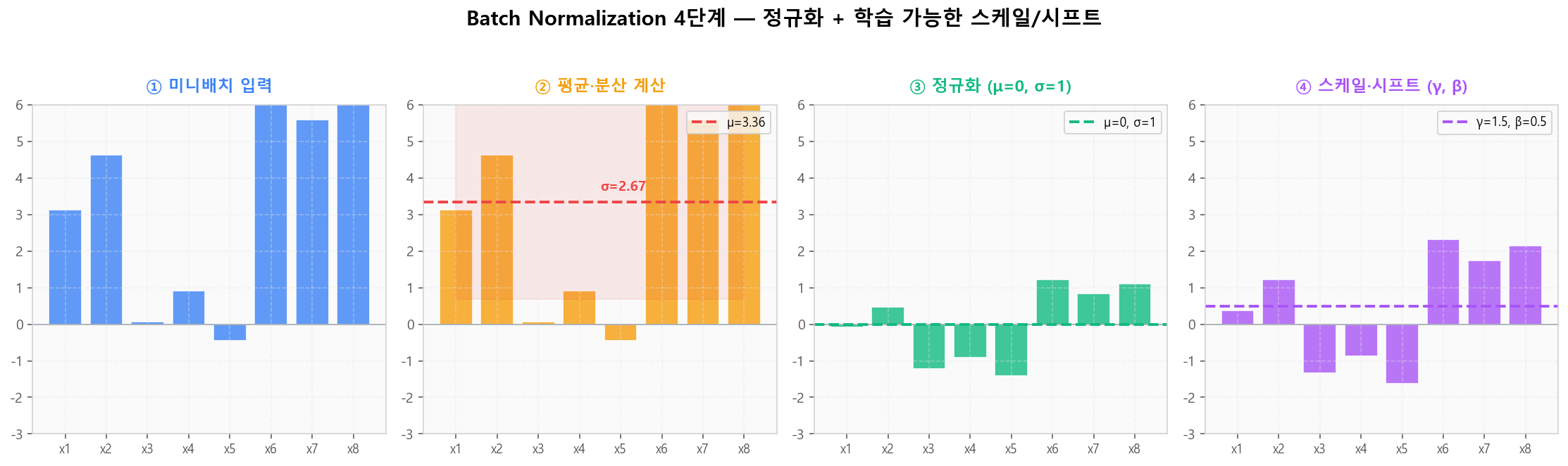 BN 4단계 — 정규화 + 학습 가능한 스케일/시프트
BN 4단계 — 정규화 + 학습 가능한 스케일/시프트배치 정규화 인터랙티브 — 활성값 분포 드리프트 비교
4층 네트워크의 각 층 활성값 분포가 학습 epoch이 진행되며 어떻게 변하는지 BN 유무에 따라 비교합니다.
관찰할 층
깊은 층(L4)일수록 드리프트가 누적되어 큼학습률 lr = 0.10
lr ≥ 0.15면 BN 없는 모델이 발산하기 시작L3 활성값 분포
학습 손실 곡선 (전체 epoch)
BN이 허용하는 큰 학습률
BN 없으면 lr=0.1은 발산합니다. BN을 추가하면 같은 lr=0.1이 안정적으로 수렴 — 약 10배 빠른 학습이 가능해집니다.
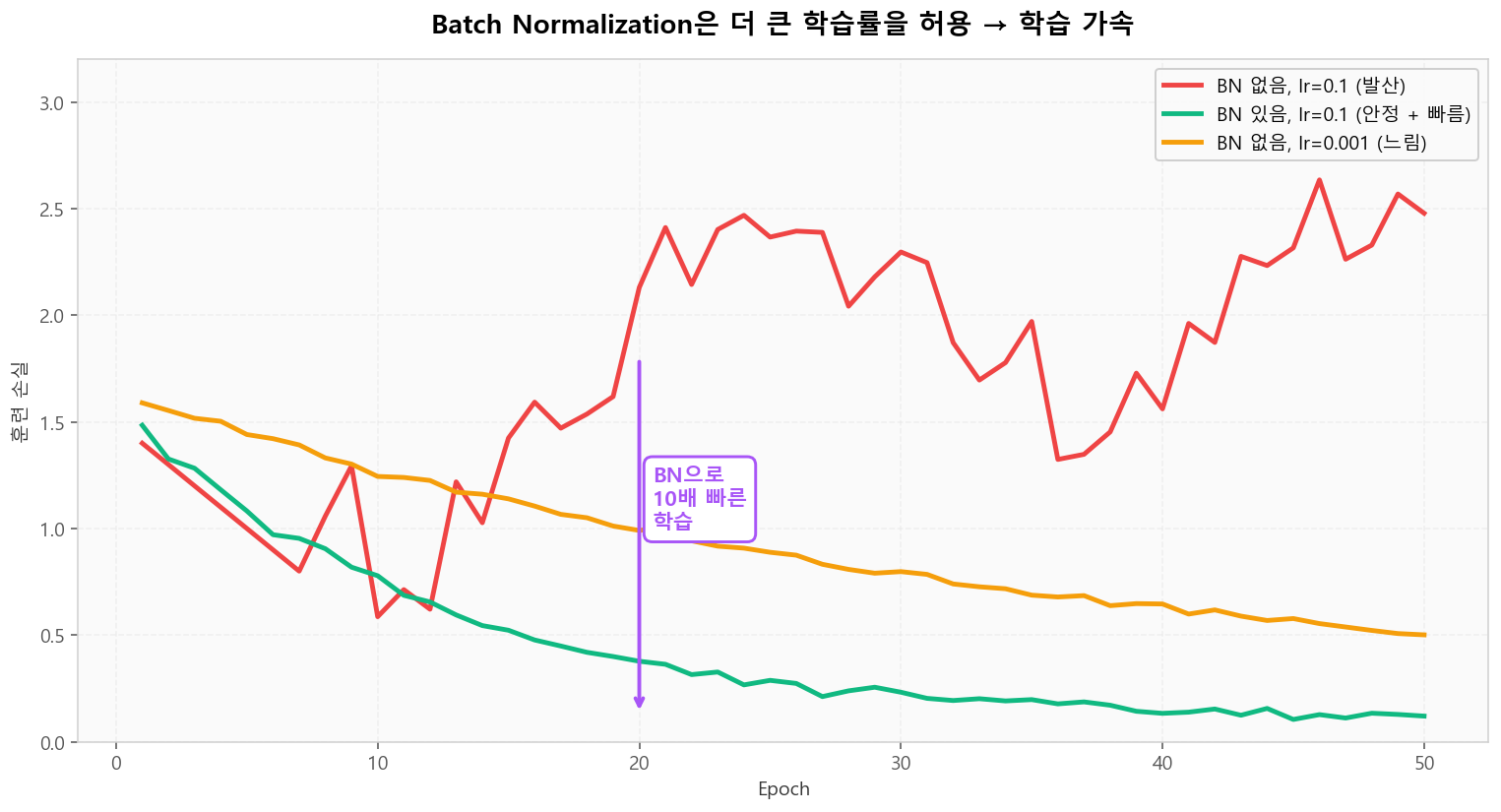 BN은 더 큰 학습률을 허용해 학습 가속
BN은 더 큰 학습률을 허용해 학습 가속📐 BN / LN / IN / GN — 어떤 차원으로 정규화?
4D 텐서 (N, C, H, W)에서 어떤 차원을 따라 평균·분산을 계산하느냐가 정규화의 종류를 결정합니다.BN은 배치, LN은 특징, IN은 샘플별 채널별, GN은 채널 그룹 단위입니다.
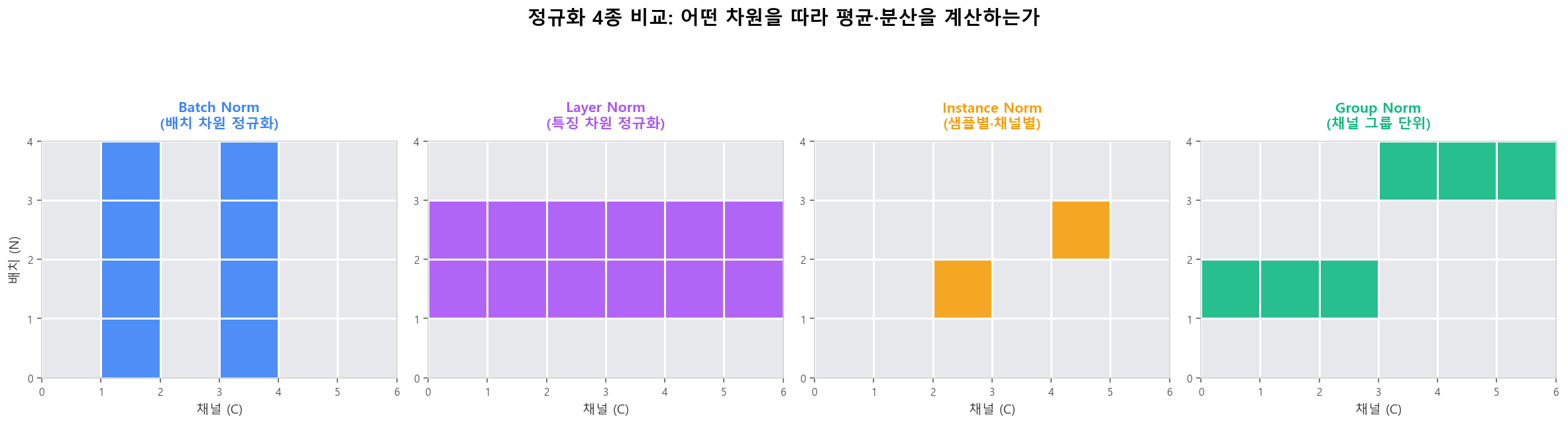 4종 정규화: 배치/특징/채널 어느 차원을 따라 평균·분산을 계산
4종 정규화: 배치/특징/채널 어느 차원을 따라 평균·분산을 계산🎭 학습 시 vs 추론 시 — BN의 두 얼굴
학습 시에는 미니배치 통계를 사용하지만 추론 시에는 학습 중 누적한 이동평균(EMA)을 사용합니다. 이 분리가 BN의 가장 까다로운 부분이며, model.eval() 호출을 잊으면 결과가 매번 달라질 수 있습니다.
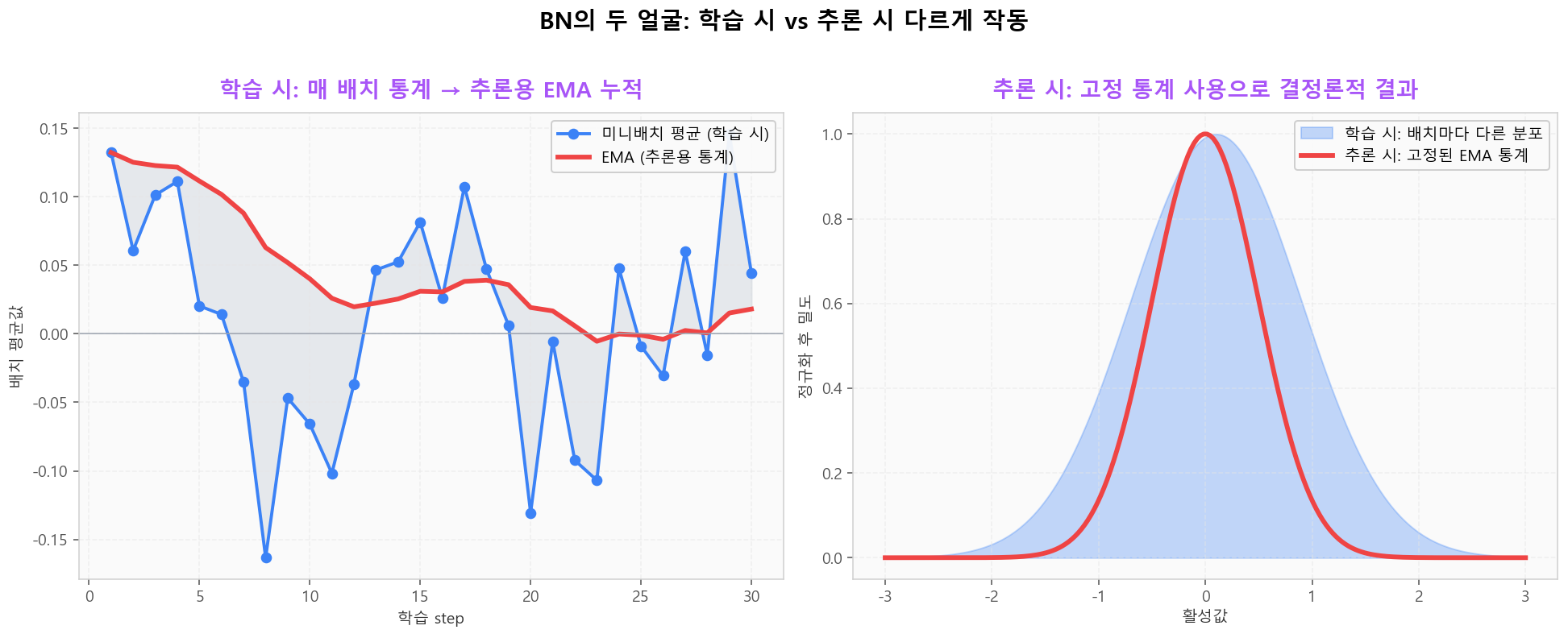 학습 시 미니배치 통계 → 추론 시 고정 EMA 통계 사용
학습 시 미니배치 통계 → 추론 시 고정 EMA 통계 사용정규화 기법별 사용 가이드
Batch Norm (BN)
CNN의 표준. 배치 ≥ 16에서 잘 작동. ResNet, EfficientNet 등 거의 모든 백본에서 사용.
Layer Norm (LN)
Transformer/RNN의 표준. 시퀀스 길이·배치 크기에 독립적. ViT, BERT, GPT 모두 LN 사용.
Group Norm (GN)
Detection/Segmentation의 표준. 배치 크기 1~4에서도 안정. Mask R-CNN 등에서 BN 대신 사용.
RMSNorm
평균 빼지 않고 RMS만으로 정규화 — 더 빠름. LLaMA, T5의 표준.
직접 해보기 — 실습 과제
- 드리프트 확인: L4 + lr=0.2 + 재생. BN 없는 분포가 점점 평균에서 멀어지고 분산이 커지는 것 관찰.
- 발산 시뮬레이션: lr=0.25로 올리고 손실 곡선 확인. BN 없는 모델이 발산하지만 BN 있는 모델은 안정.
- 층별 영향: L1 → L4로 옮겨가며 epoch 30 시점 비교. 깊은 층일수록 BN 없는 분포의 드리프트가 심함.
- 이론과 연결: 위 4종 정규화 다이어그램과 사용 가이드를 비교하며 "내 프로젝트에는 어떤 정규화가 맞을까?" 판단해보세요.