
넘스탯
DATA ANALYTICS & INSIGHTS
확률에서 LLM까지 – 데이터 사이언스 전문 교육 플랫폼
Gradient 문제 실습실
Vanishing / Exploding — 깊이가 만드는 함정과 LSTM·ResNet의 해결책
원하는 개념·랩·가이드를 검색해보세요
Ctrl K층이 깊어질수록 신호가 사라지거나 폭발한다
이 페이지에서 배우고 나면
- 기울기 소실·폭발이 왜 생기는지 층 깊이와 함께 관찰할 수 있습니다.
- 활성화 함수와 가중치 초기화가 이 문제에 미치는 영향을 확인할 수 있습니다.
- 이 문제를 완화하는 기법들이 어떻게 작동하는지 이해할 수 있습니다.
📉 깊이가 만드는 지수적 함정
Sigmoid 미분 최대값이 0.25라서, 10층만 쌓아도 gradient 곱이 0.25¹⁰ ≈ 1e-6로 거의 0이 됩니다. 반대로 가중치가 1.5인 경우 30층에서 1.5³⁰ ≈ 1.9e+5로 폭주. 깊이는 신경망의 힘이지만 동시에 함정입니다.
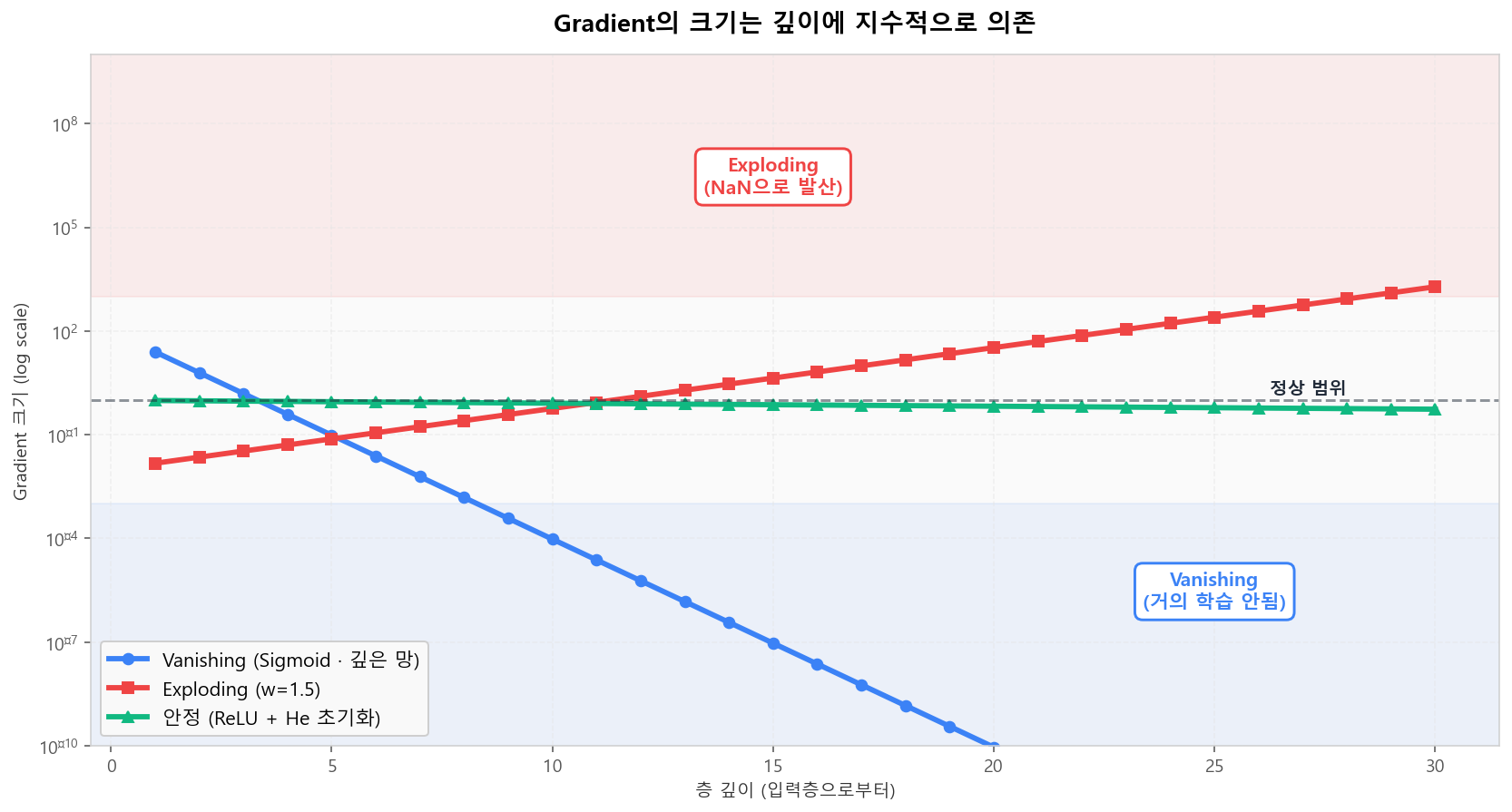 깊이에 따른 Gradient의 지수적 변화 (log scale)
깊이에 따른 Gradient의 지수적 변화 (log scale)📐 활성화 함수가 Gradient를 결정한다
Sigmoid 미분 최대 0.25 — 깊이가 누적되면 vanishing 보장. Tanh는 최대 1.0이지만 양 끝에서 포화. ReLU는 양수 영역에서 미분이 1이라 신호가 깊이를 거쳐도 보존됩니다 — 2010년대 ReLU 혁명의 핵심 이유.
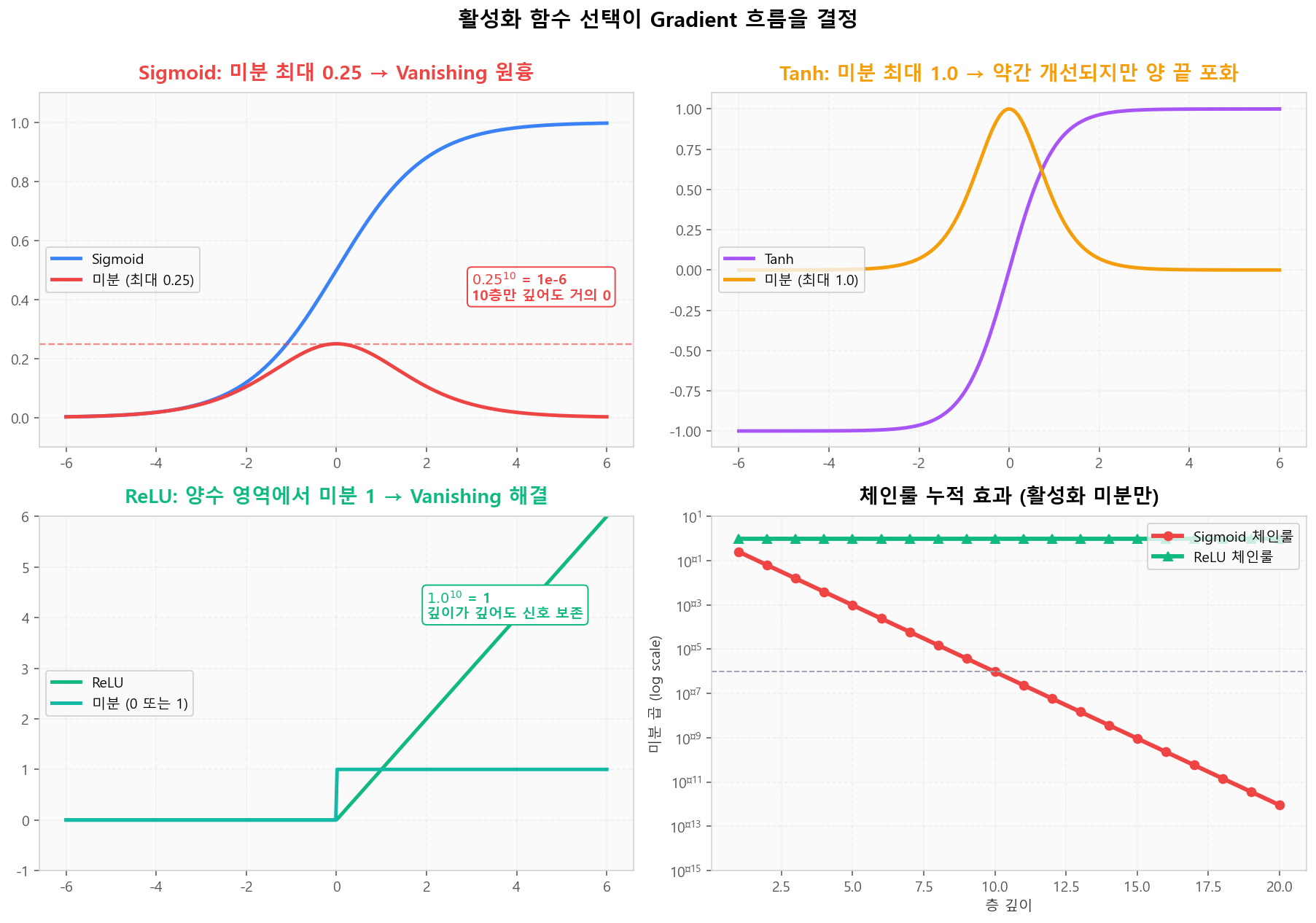 활성화 함수와 그 미분 — 체인룰 누적 효과 비교
활성화 함수와 그 미분 — 체인룰 누적 효과 비교Gradient 흐름 인터랙티브 — Vanishing/Exploding 시뮬레이터
활성화 함수·가중치 초기화·Skip Connection 조합에 따라 깊이별 gradient 크기가 어떻게 변하는지 직접 비교하세요.
활성화 함수
Sigmoid (max 0.25)가중치 초기화
Naive (N(0,1))Skip Connection
네트워크 깊이 = 30층
Skip Connection: Gradient의 고속도로
잔차 블록 y = F(x) + x의 미분은 ∂y/∂x = ∂F/∂x + I — 항상 항등행렬 I가 더해집니다. F의 미분이 매우 작아져도 I가 1을 보존해 gradient가 깊은 층까지 흐릅니다. ResNet 152층이 학습 가능해진 이유입니다.
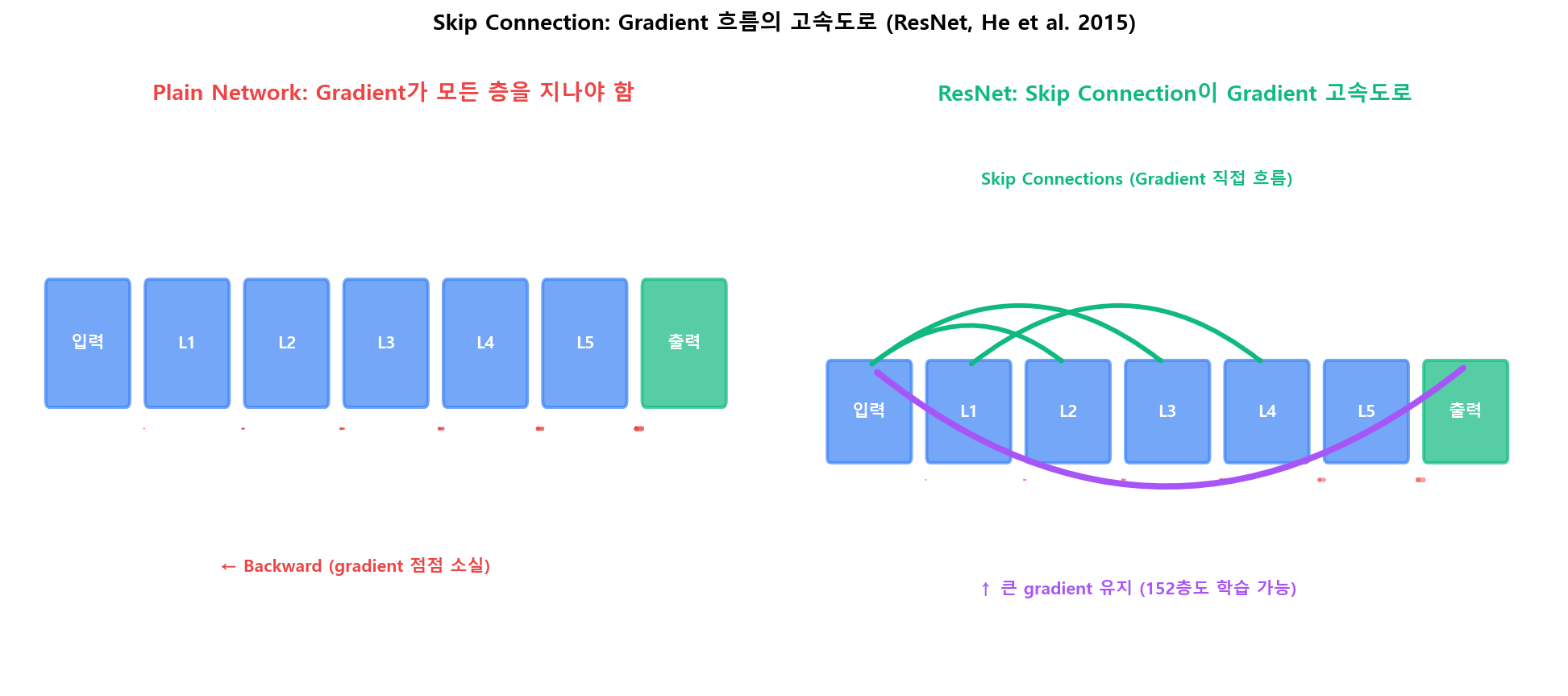 ResNet의 Skip Connection — Gradient가 직접 흐를 우회 경로
ResNet의 Skip Connection — Gradient가 직접 흐를 우회 경로Gradient Clipping: Exploding을 막는 가장 단순한 방법
Gradient 노름이 임계값을 넘으면 그 임계값으로 잘라냅니다. RNN과 LLM 학습의 사실상 필수 요소이며, 학습 중 손실이 갑자기 NaN으로 발산하면 가장 먼저 시도해야 할 해결책입니다.
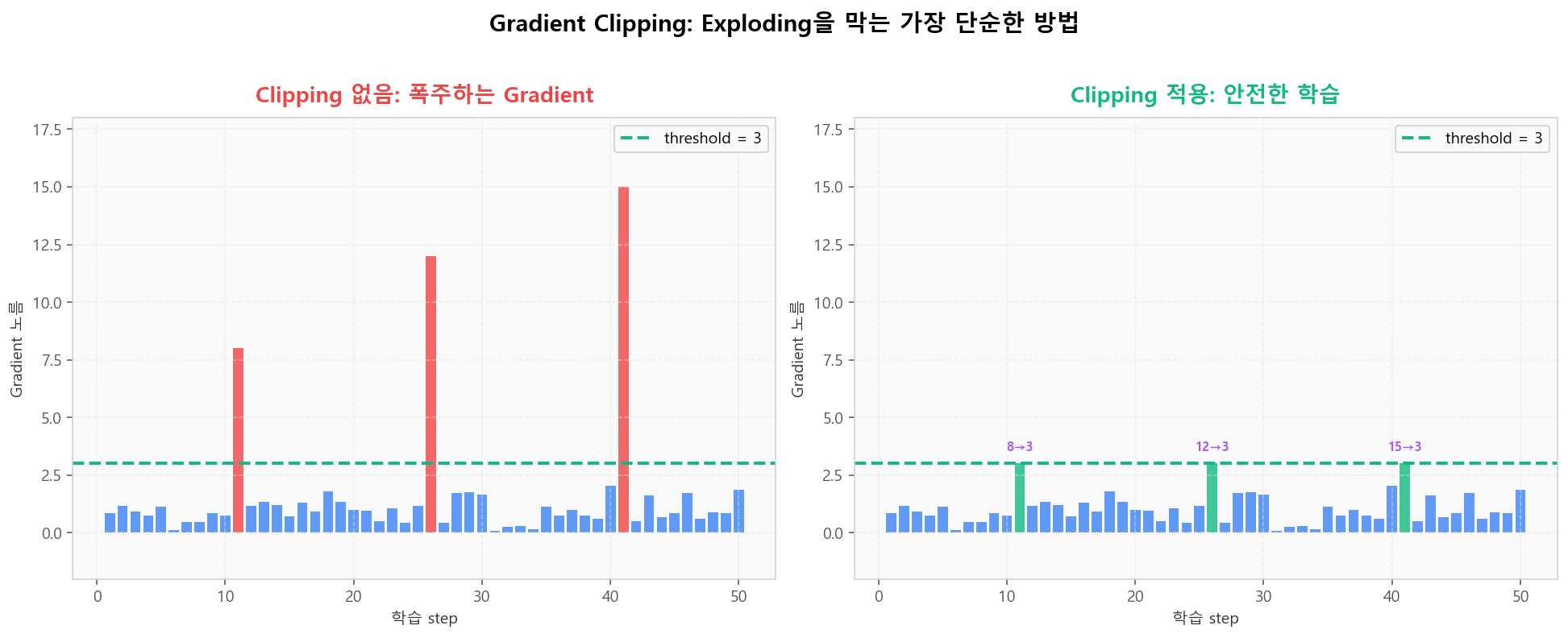 Gradient Clipping: 폭주 step을 임계값으로 잘라 학습 안정화
Gradient Clipping: 폭주 step을 임계값으로 잘라 학습 안정화가중치 초기화: 분산을 fan_in으로 정규화
잘못된 초기화는 첫 forward pass부터 활성값을 폭주/소실시킵니다.Xavier(1/fan_in)는 Sigmoid/Tanh용, He(2/fan_in)는 ReLU용으로 ReLU가 음수 절반을 0으로 만든다는 사실을 보상합니다.
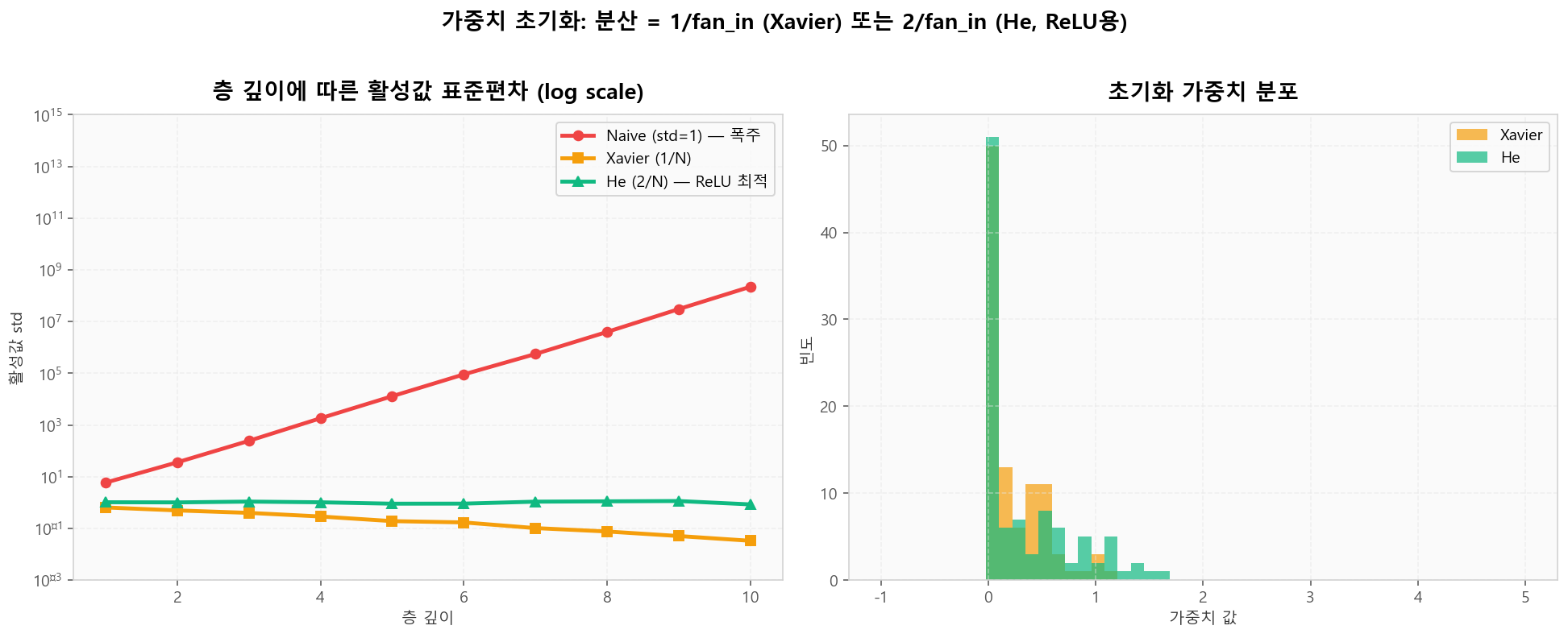 초기화 방법별 깊은 망의 활성값 분산 (10층 시뮬레이션)
초기화 방법별 깊은 망의 활성값 분산 (10층 시뮬레이션)Gradient 문제 해결책 가이드
1. ReLU 계열 활성화
양수 영역 미분 1.0 → vanishing 방지. ReLU, Leaky ReLU, GELU, Swish.
2. He/Xavier 초기화
활성화에 맞는 분산으로 초기화. PyTorch/Keras 기본값 신뢰.
3. Skip Connection
잔차 연결로 gradient 고속도로 제공. ResNet, Transformer가 필수 사용.
4. Gradient Clipping
노름이 임계값 초과 시 잘라냄. RNN/LLM 필수, NaN 방지의 첫 번째 도구.
직접 해보기 — 실습 과제
- 1990년대 한계 재현: Sigmoid + Naive + Skip OFF + 30층. Gradient가 1e-15로 vanishing — 학습 불가능.
- 한 가지씩 고쳐가기: Sigmoid → ReLU, Naive → He, Skip OFF → ON. 각 단계마다 gradient가 어떻게 회복되는지 관찰.
- Skip의 위력 체감: 어떤 활성화/초기화 조합이든 Skip ON으로 바꾸면 50층에서도 안정. 이것이 ResNet 152층이 학습 가능한 이유.
- Exploding 만들기: Tanh + Naive로 30층 → gradient가 1e+10 이상 발산. 실무에서는 Gradient Clipping으로 잡습니다.