
넘스탯
DATA ANALYTICS & INSIGHTS
확률에서 LLM까지 – 데이터 사이언스 전문 교육 플랫폼
활성화 함수 실습실
Sigmoid · Tanh · ReLU · Leaky ReLU · GELU — 비선형성이 신경망을 가능하게 한다
원하는 개념·랩·가이드를 검색해보세요
Ctrl K선을 그어서는 풀 수 없는 문제, 비선형이 답이다
이 페이지에서 배우고 나면
- 활성화 함수가 없으면 왜 층을 쌓아도 소용없는지 이해할 수 있습니다.
- ReLU·Sigmoid·Tanh의 모양과 특성 차이를 직접 비교할 수 있습니다.
- 활성화 함수 선택이 학습에 어떤 영향을 주는지 관찰할 수 있습니다.
📐 5종 활성화 함수 한눈에 보기
왼쪽은 함수 자체, 오른쪽은 미분. 미분이 곧 gradient의 원천이므로 미분 모양이 학습 동작을 결정합니다.
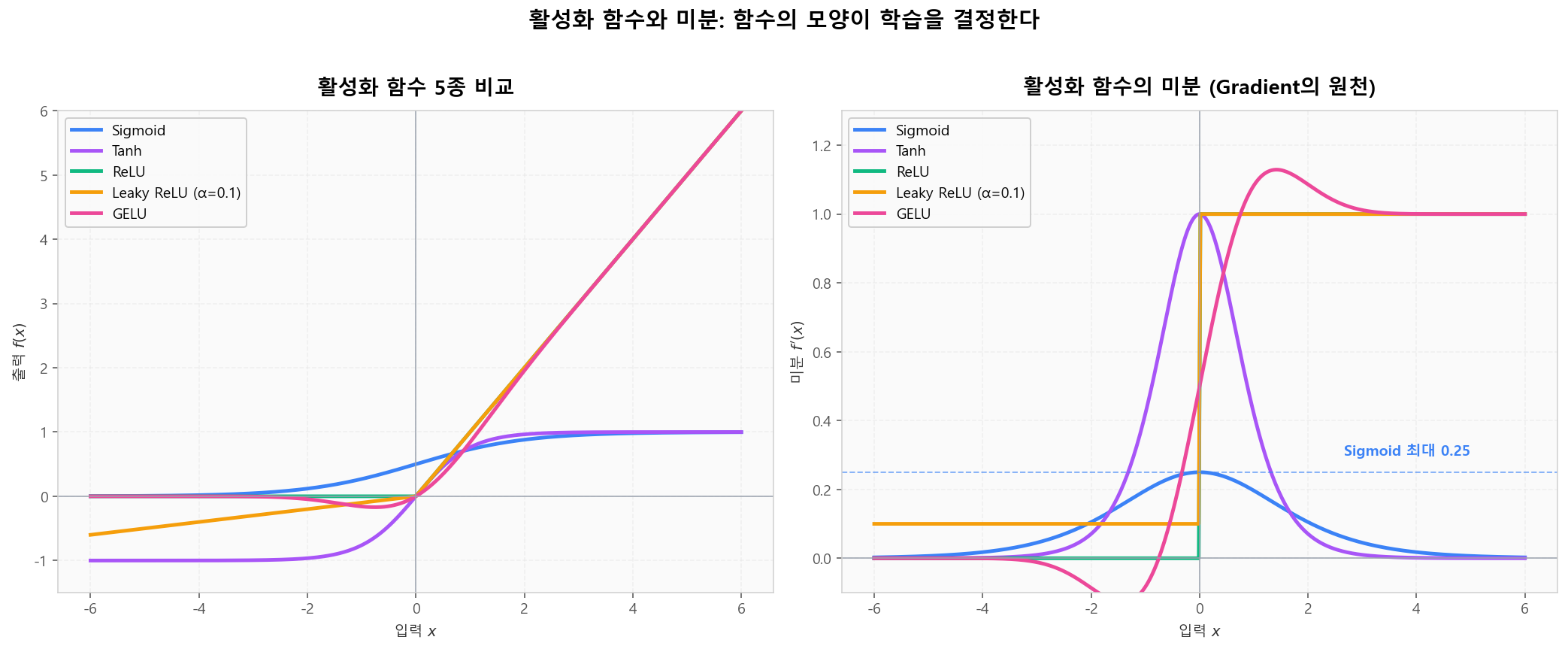 5종 활성화 함수와 그 미분 — Sigmoid·Tanh·ReLU·Leaky ReLU·GELU
5종 활성화 함수와 그 미분 — Sigmoid·Tanh·ReLU·Leaky ReLU·GELU활성화 함수 인터랙티브 비교
5종 활성화 함수의 모양과 미분을 동시에 비교하고, 특정 입력값에서의 정확한 값을 슬라이더로 확인하세요.
표시할 활성화 함수
입력값 x = 0.50
Leaky ReLU α = 0.10
α=0이면 일반 ReLU와 동일활성화 함수 f(x)— 좌축: Bounded(Sigmoid/Tanh), 우축: Unbounded(ReLU 계열)
미분 f'(x) — Gradient의 원천
x = 0.50에서의 값 비교
깊이 효과: 10층에서 활성화 미분 곱
📉 Sigmoid의 포화 문제 — Vanishing의 원흉
Sigmoid 미분의 최대값은 0.25, 양 끝에서는 거의 0. 10층 깊이만 누적되어도 gradient 곱이0.25¹⁰ ≈ 1e-6로 사라집니다 — 2010년대 이전 깊은 신경망 학습 실패의 주된 원인이었습니다.
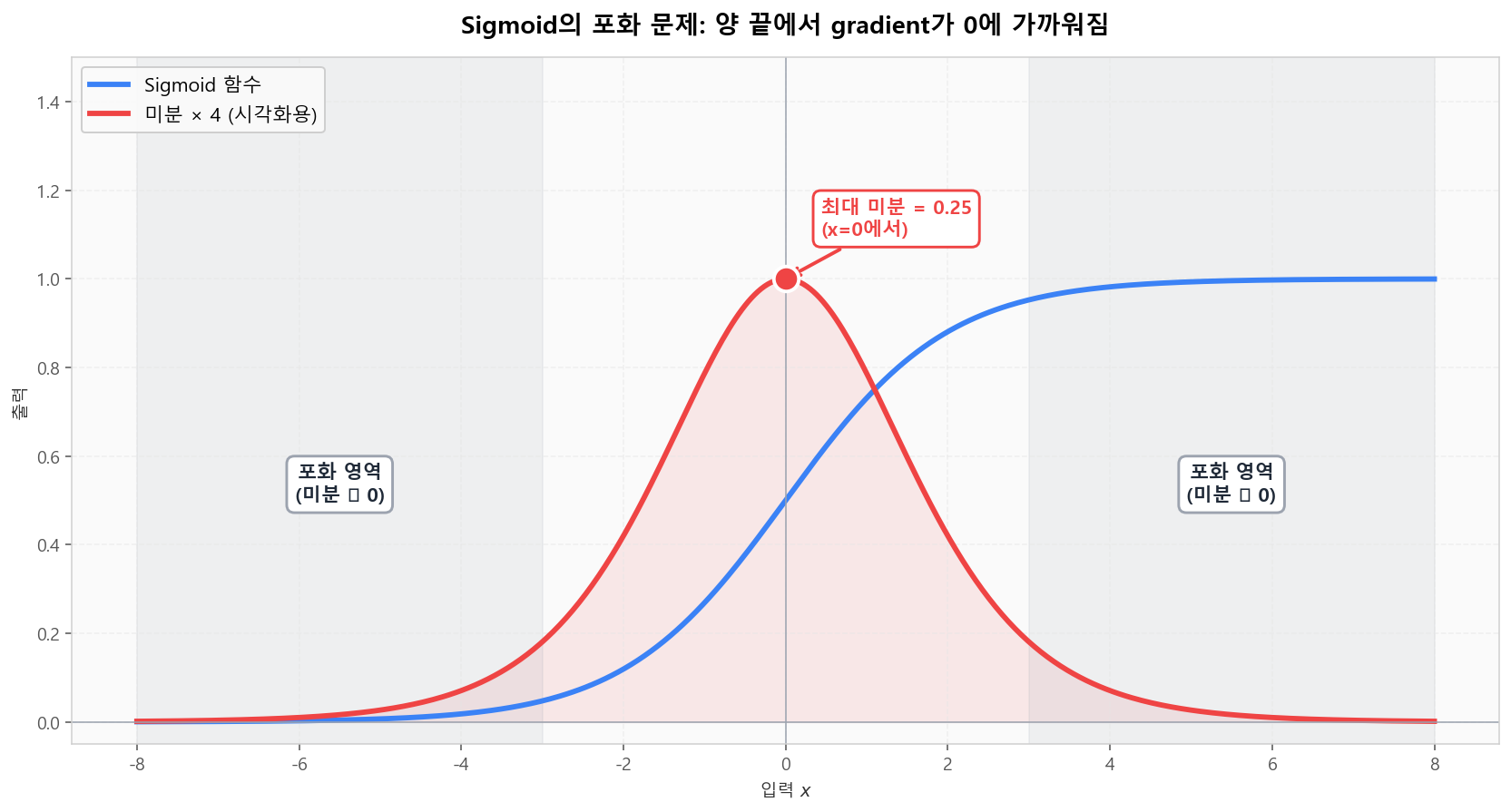 Sigmoid의 양 끝 포화 영역: 미분이 거의 0이 되어 gradient가 사라짐
Sigmoid의 양 끝 포화 영역: 미분이 거의 0이 되어 gradient가 사라짐💀 Dead ReLU 문제와 Leaky ReLU의 해결책
ReLU는 음수 영역 미분이 정확히 0. 학습 중 어떤 뉴런이 한 번 음수 입력만 받게 되면 gradient가 0이어서 영원히 학습되지 않습니다 — Dead ReLU. Leaky ReLU는 작은 음수 기울기 α를 두어 이를 방지합니다.
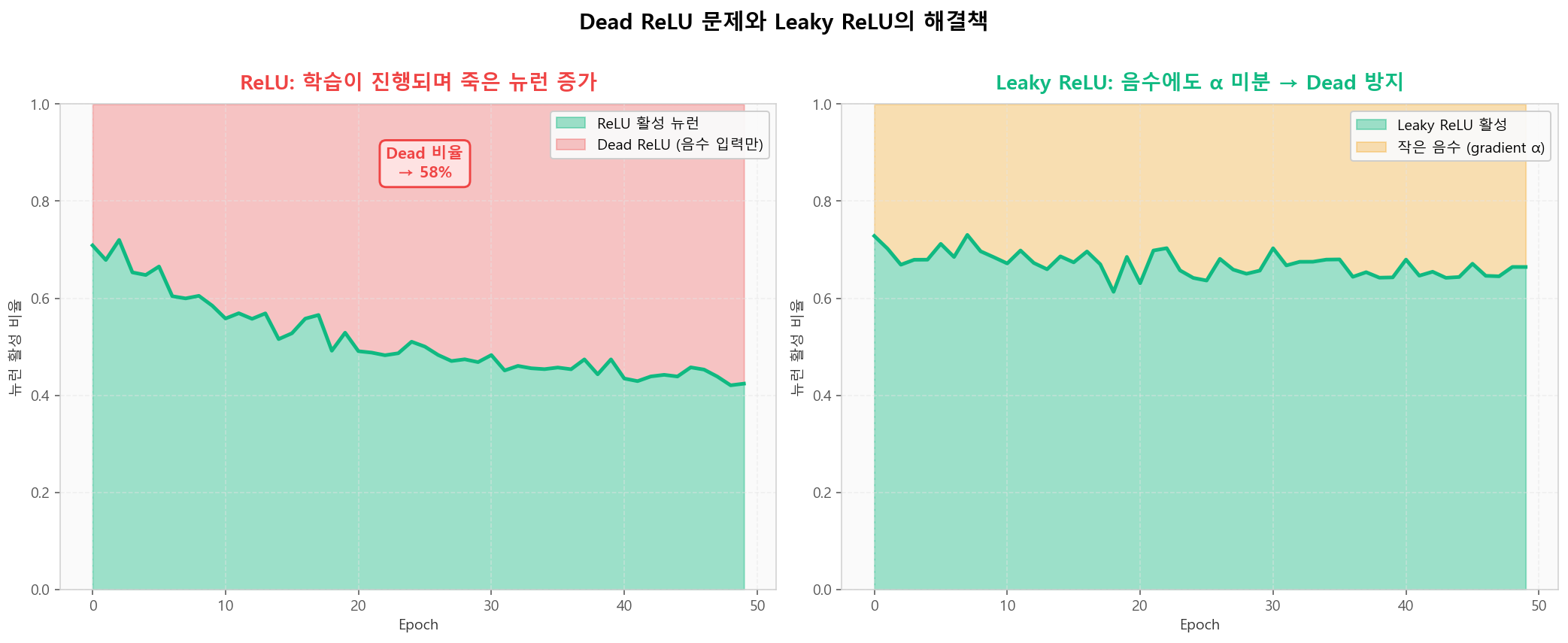 ReLU의 Dead 뉴런 증가 vs Leaky ReLU의 안정 활성
ReLU의 Dead 뉴런 증가 vs Leaky ReLU의 안정 활성깊이 누적 효과 — 활성화 선택이 학습 가능성을 결정
체인룰로 활성화 미분이 곱해집니다. 평균 미분이 작을수록 깊이 누적이 빠르게 vanishing 영역에 진입합니다. ReLU 계열(평균 ≈ 0.5)만이 깊은 네트워크에서 살아남는 이유입니다.
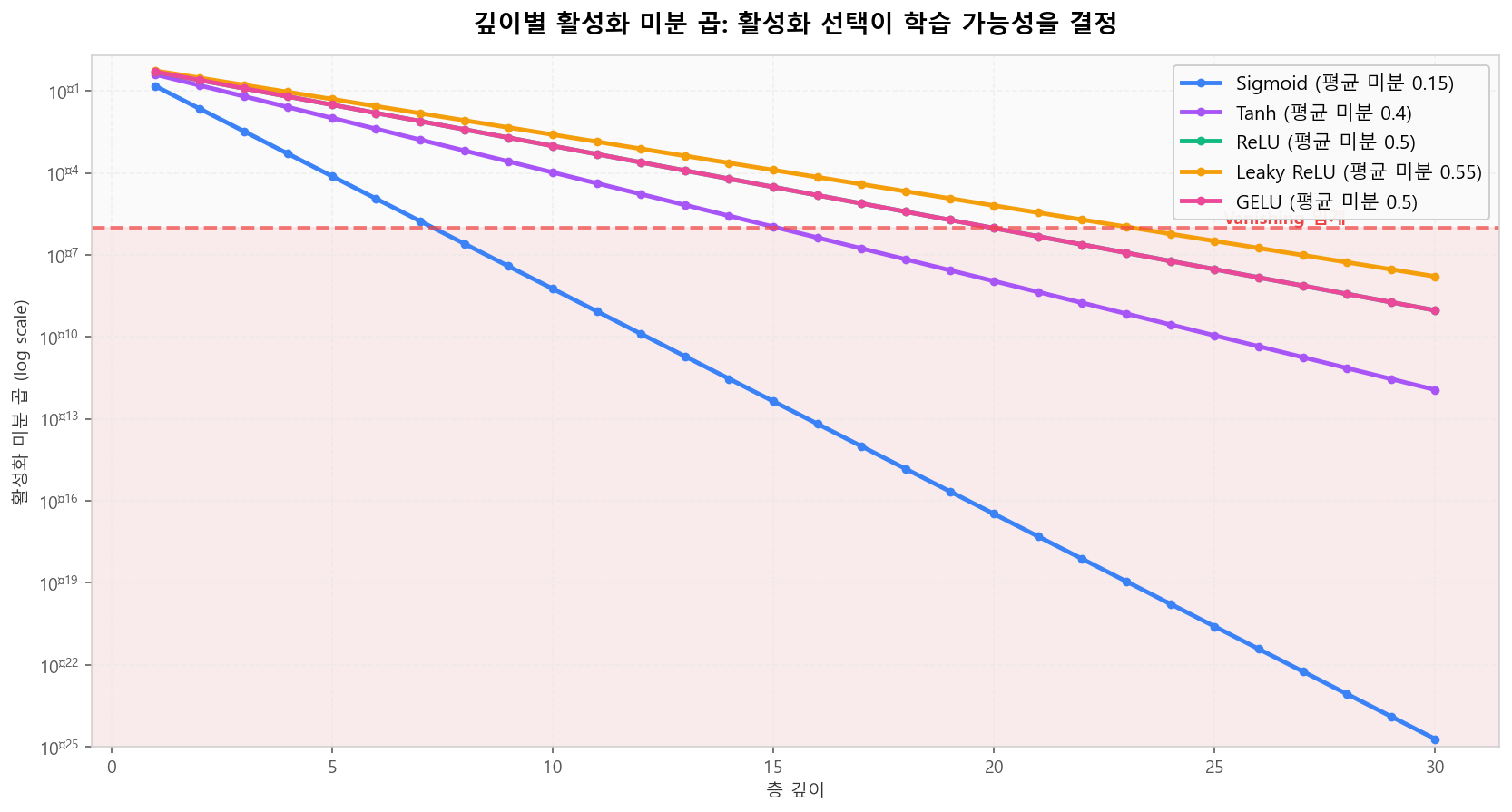 활성화별 깊이 누적 미분 — Sigmoid는 8층 만에 1e-6 이하로 소실
활성화별 깊이 누적 미분 — Sigmoid는 8층 만에 1e-6 이하로 소실출력층 활성화 함수 선택 가이드
은닉층에는 ReLU 계열이 표준이지만, 출력층은 문제 유형에 따라 달라집니다. 회귀는 선형, 이진 분류는 Sigmoid, 다중 분류는 Softmax, 다중 라벨은 독립 Sigmoid.
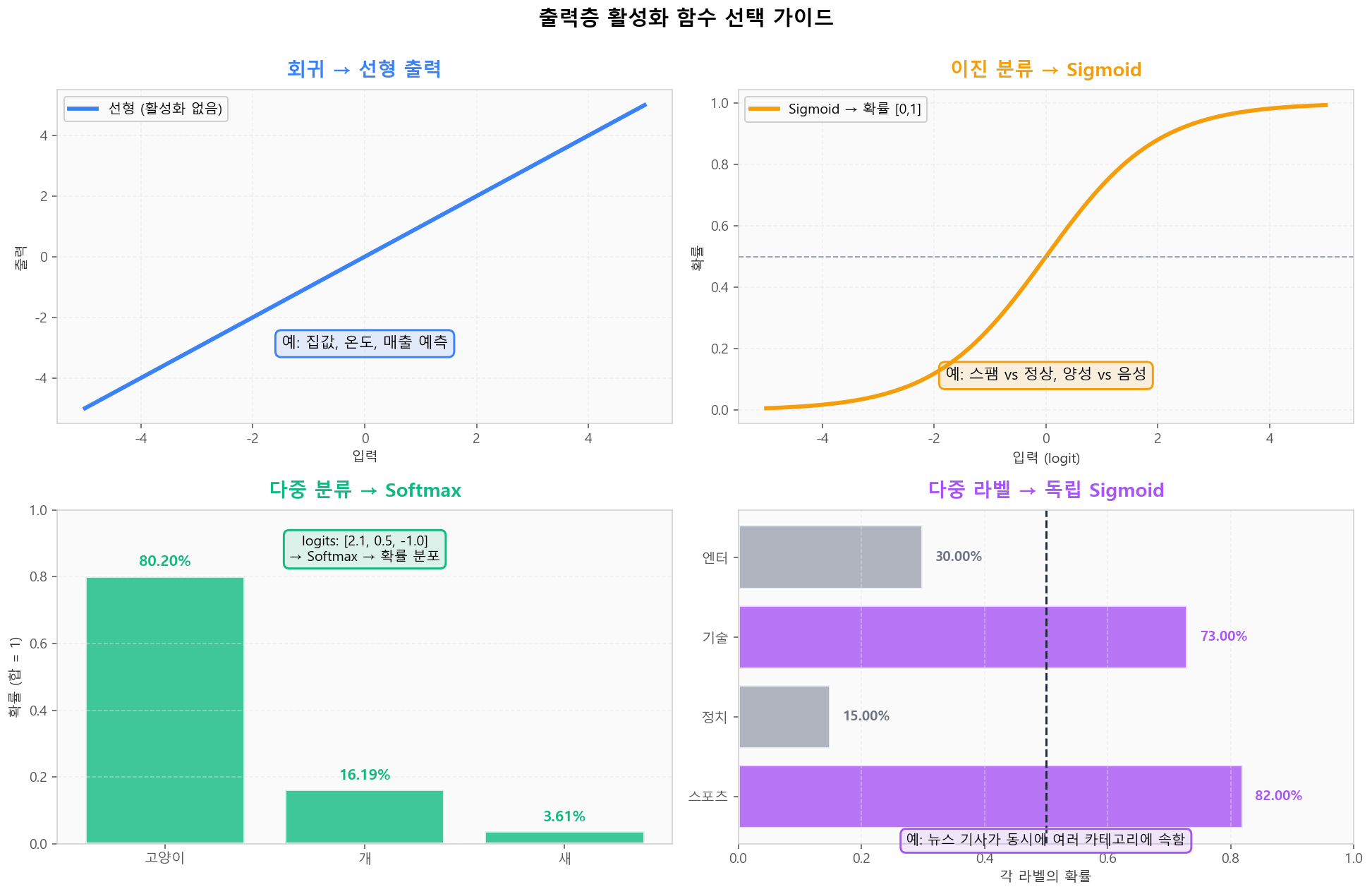 출력층 활성화 함수 선택: 문제 유형이 결정한다
출력층 활성화 함수 선택: 문제 유형이 결정한다활성화 함수 선택 가이드
ReLU — 은닉층의 기본값
계산 빠르고 vanishing 없음. CNN의 표준. 다만 Dead ReLU 주의.
Leaky ReLU / PReLU
Dead ReLU 문제 회피. α=0.01~0.2 일반적. GAN에서 자주 사용.
GELU / Swish — Transformer 표준
x=0 근처 부드러움이 학습 안정성에 기여. BERT/GPT/ViT의 표준.
Sigmoid / Tanh — 출력층 또는 게이트
은닉층 사용 비추천. 이진 분류 출력층(Sigmoid)이나 LSTM 게이트(Tanh)에 적합.
직접 해보기 — 실습 과제
- 포화 영역 체감: Sigmoid만 활성. 입력 x를 ±5로 옮기면 미분이 거의 0임을 확인.
- Dead ReLU: ReLU만 활성. x = -2로 두면 출력 0, 미분 0 — 학습 신호 없음.
- Leaky ReLU 비교: Leaky ReLU 활성 + α=0.1. 같은 x = -2에서 미분 0.1 → 학습 가능.
- GELU의 부드러움: GELU와 ReLU를 동시에 활성. x = 0 근처에서 GELU는 부드럽지만 ReLU는 꺾임.
- 깊이 누적 확인: 깊이를 15층 이상으로 올리세요. Sigmoid는 vanishing, ReLU/Leaky/GELU는 살아있음.