
넘스탯
DATA ANALYTICS & INSIGHTS
확률에서 LLM까지 – 데이터 사이언스 전문 교육 플랫폼
손실 함수 실습실
MSE·MAE·Huber·Cross-Entropy를 직접 조작하며 "어떤 손실이 어떤 모양인지" 체감하세요
원하는 개념·랩·가이드를 검색해보세요
Ctrl K모델에게 '얼마나 틀렸는지' 알려주는 잣대
이 페이지에서 배우고 나면
- 회귀(MSE)와 분류(교차 엔트로피)에서 손실 함수가 어떻게 다른지 직접 비교할 수 있습니다.
- 손실 값이 어떻게 학습을 이끄는지(경사의 방향) 이해할 수 있습니다.
- 문제에 맞지 않는 손실을 쓰면 왜 학습이 어긋나는지 확인할 수 있습니다.
📐 MSE: 잔차의 제곱 평균
회귀선과 실제 값의 차이(잔차)가 손실의 근원입니다. MSE는 이 잔차를 제곱해서 평균합니다 — 큰 잔차일수록 손실이 가속도로 커지는 이유입니다.
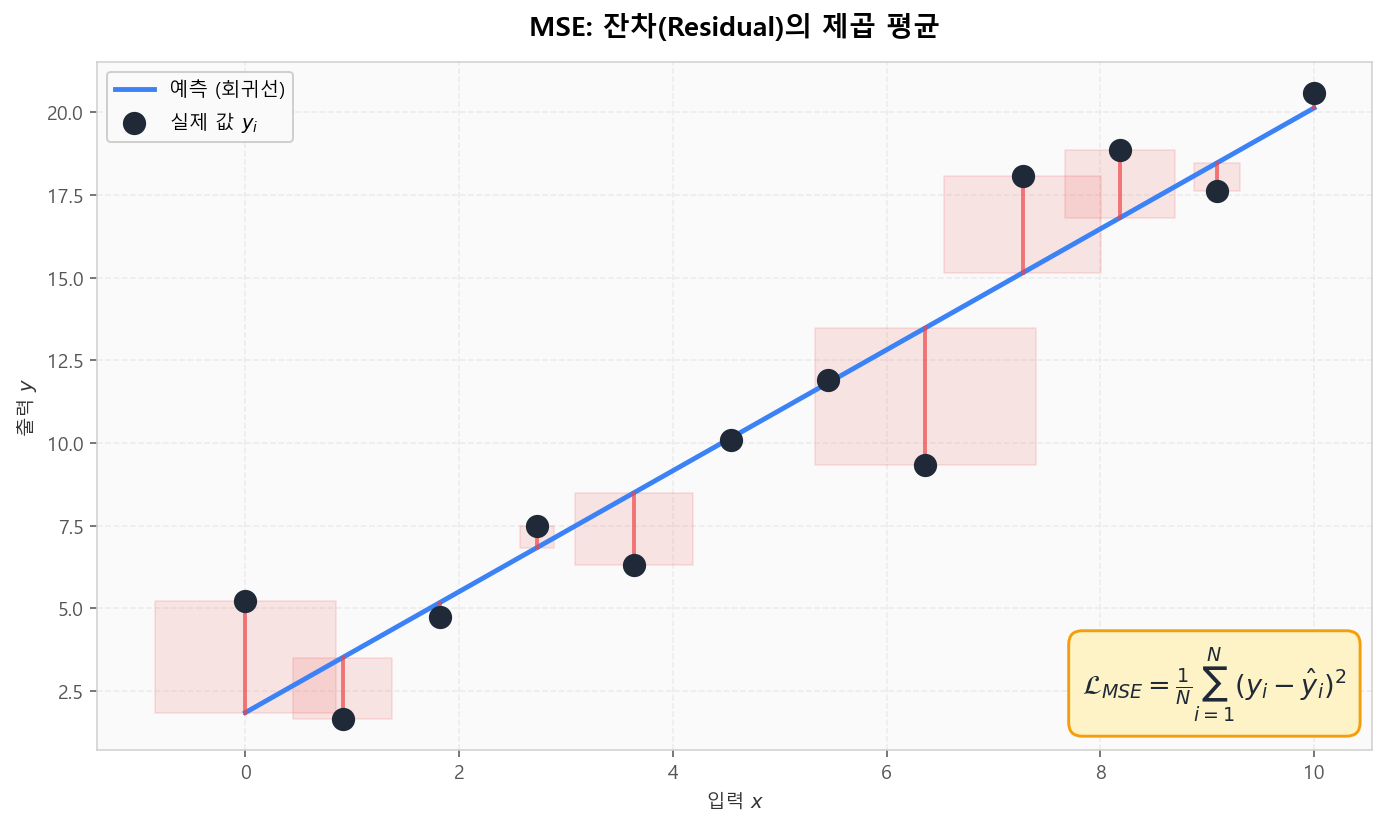 MSE: 예측선과 실제 값의 차이(잔차)를 제곱하여 평균
MSE: 예측선과 실제 값의 차이(잔차)를 제곱하여 평균Cross-Entropy의 본질: −log(p)
분류에서 모델이 "정답 클래스에 부여한 확률 p"의 −log가 손실입니다. p가 1에 가까우면 손실 ≈ 0, p가 0.01이면 손실 ≈ 4.6 — 확신 있는 오답에 폭발적 페널티를 주는 곡선의 모양입니다.
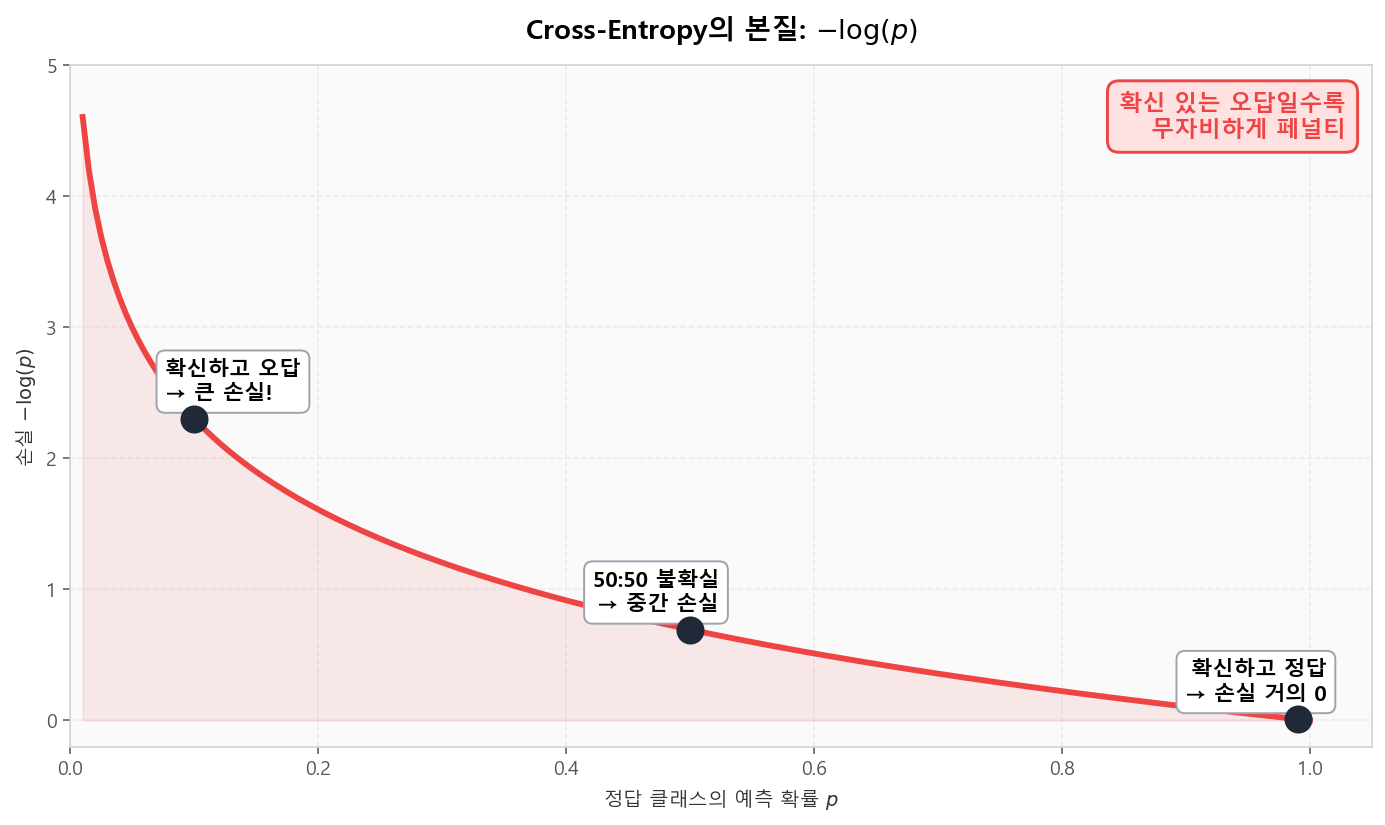 −log(p) 곡선: 확신 있는 오답일수록 손실이 폭발적으로 증가
−log(p) 곡선: 확신 있는 오답일수록 손실이 폭발적으로 증가손실 함수 인터랙티브 비교
정답값과 예측값을 직접 움직여보며 MSE, MAE, Huber, Cross-Entropy의 모양과 값을 동시에 비교해보세요.
손실 함수 선택
정답값 y = 1.00
예측값 ŷ = 0.700
MSE vs MAE: 아웃라이어 민감도
같은 오차 +3에 대해 MSE는 9, MAE는 3을 반환합니다. 이상치(outlier)가 많은 데이터에서 MSE가 휘둘리는 이유이자, MAE/Huber로 대체하는 동기입니다.
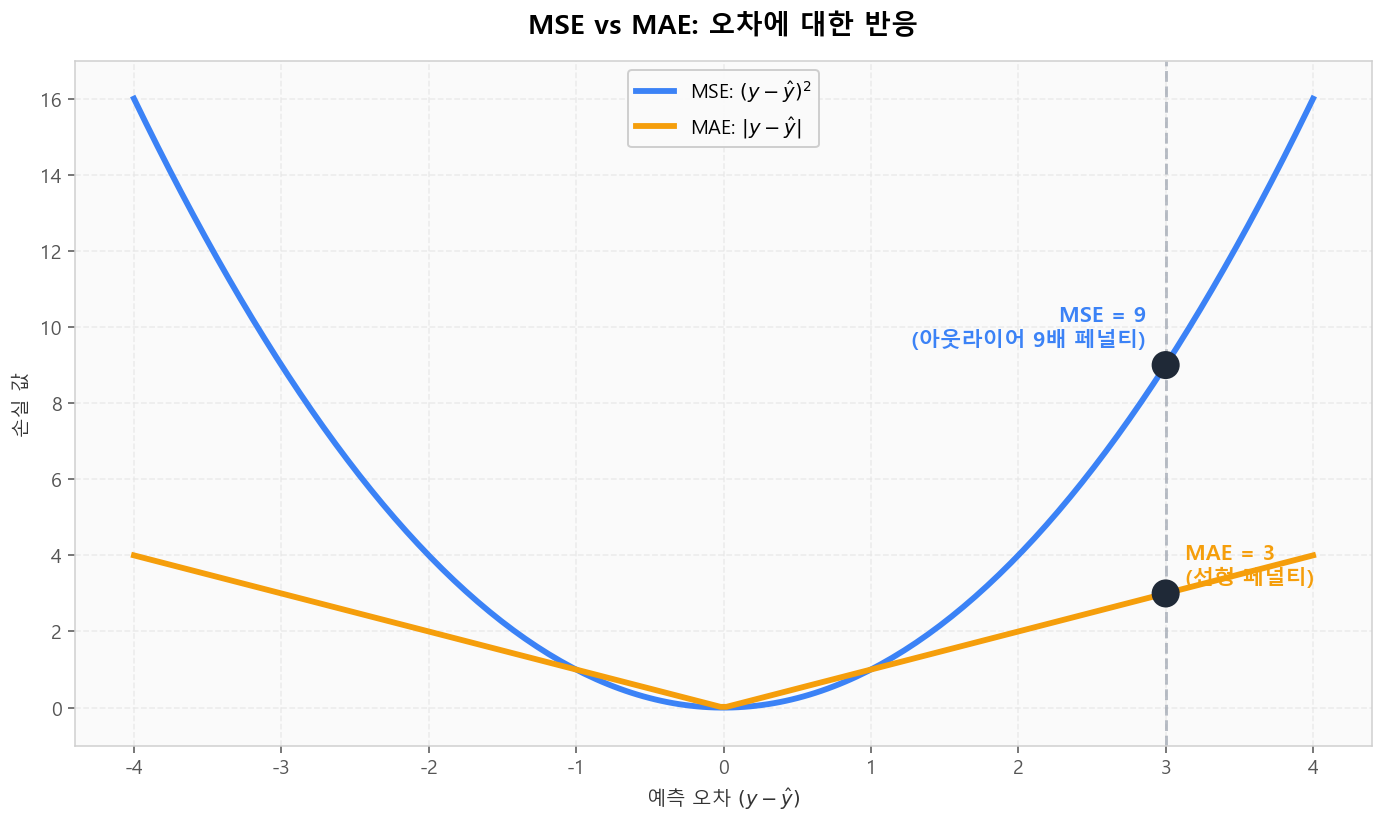 MSE는 아웃라이어에 민감, MAE는 선형 페널티
MSE는 아웃라이어에 민감, MAE는 선형 페널티다중 분류 Cross-Entropy: 분포 간 거리
정답 분포(one-hot)와 예측 확률 분포가 가까울수록 CE는 작아집니다. 좋은 예측(CE ≈ 0.16)과 나쁜 예측(CE ≈ 1.61)을 시각적으로 비교해보세요.
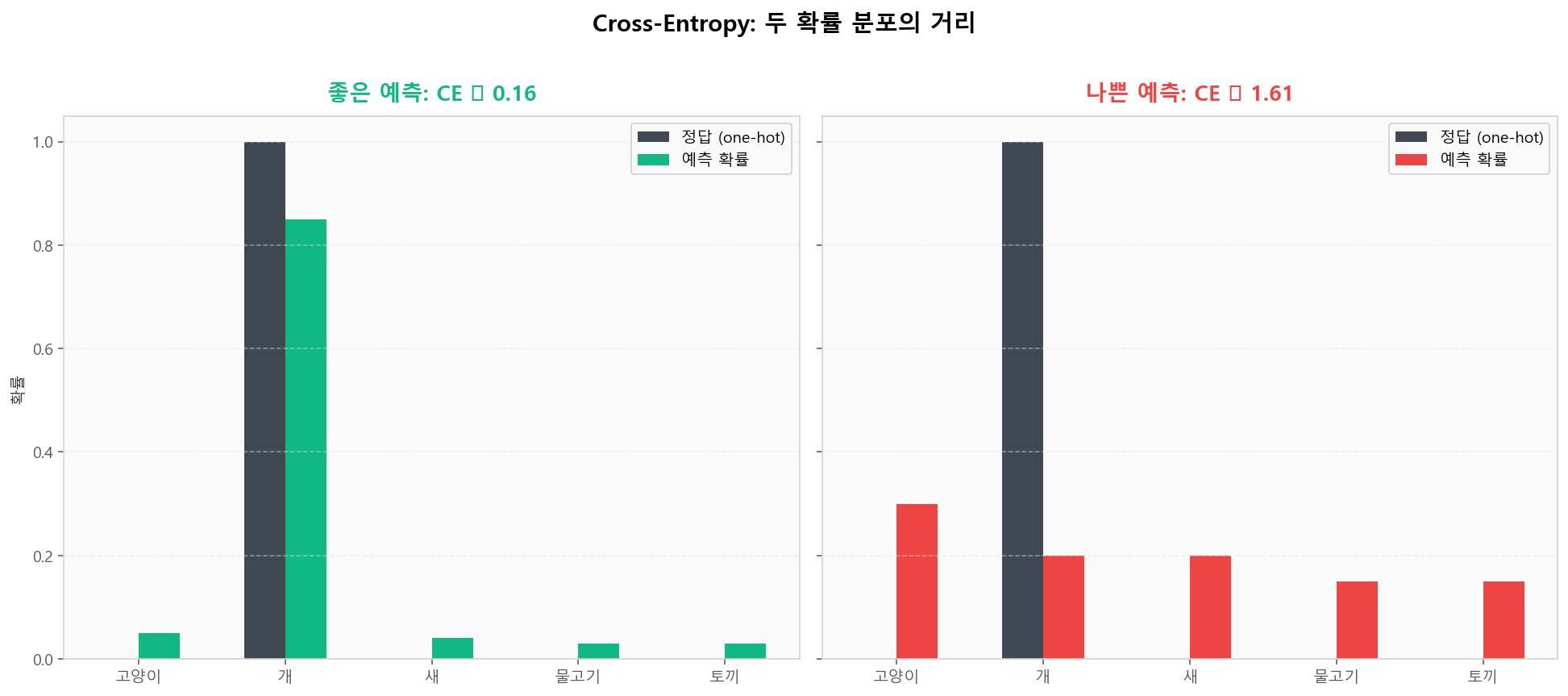 Cross-Entropy는 예측 확률 분포와 정답 분포의 거리를 측정
Cross-Entropy는 예측 확률 분포와 정답 분포의 거리를 측정손실 표면: 옵티마이저의 지형
가중치 공간에서 손실을 표면으로 그리면 "옵티마이저가 찾아가는 지형"이 됩니다.★ 표시가 최저점(Global Minimum) — 다음 단원 옵티마이저 실습에서 SGD/Momentum/Adam이 이 지형을 어떻게 탐색하는지 직접 비교합니다.
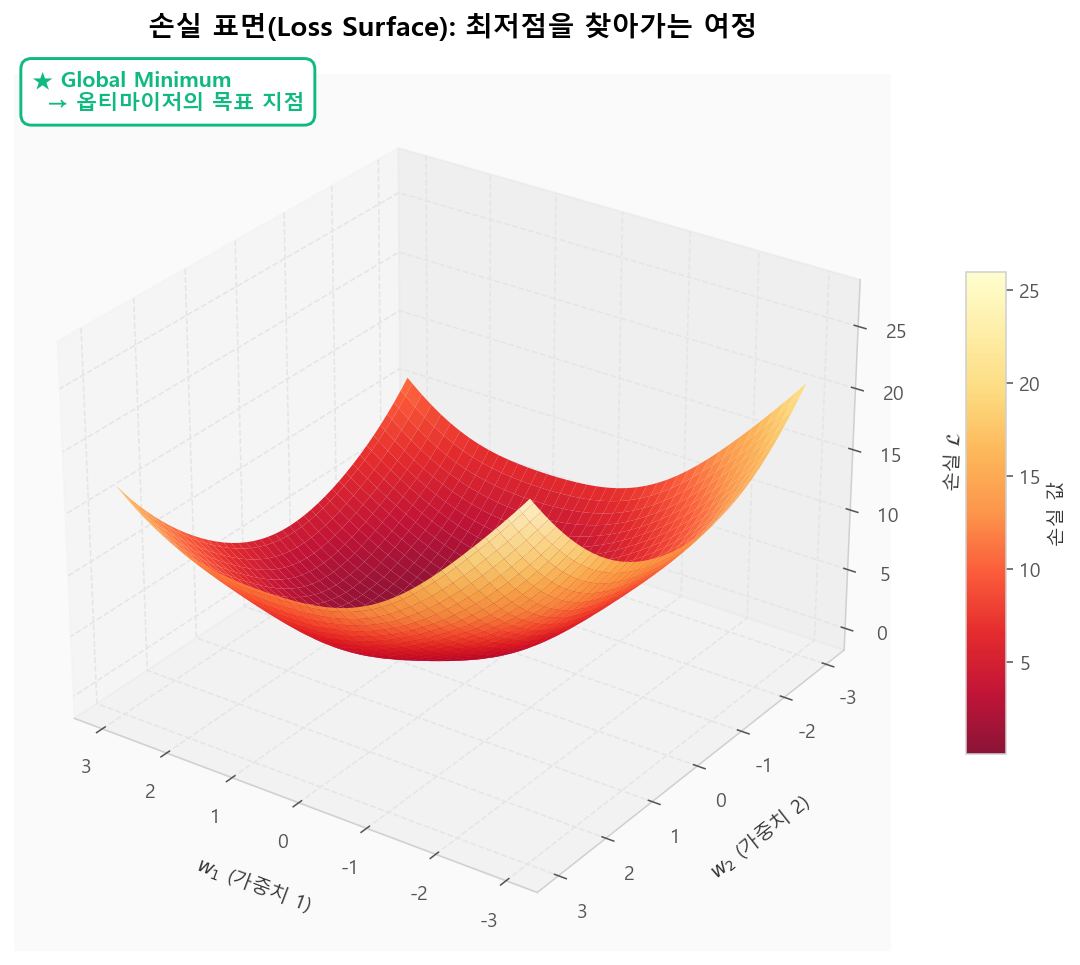 손실 표면: 옵티마이저가 최저점을 찾아가는 지형
손실 표면: 옵티마이저가 최저점을 찾아가는 지형어떤 손실을 언제 쓸까?
MSE — 회귀의 표준
실수값을 예측하는 회귀 문제의 기본값. 큰 오차에 엄격하며 미분이 깔끔합니다.
MAE / Huber — 이상치 강건
이상치(outlier)가 많은 데이터에서 MSE는 흔들리지만 MAE/Huber는 견고합니다.
Binary CE — 이진 분류
Sigmoid 출력과 짝을 이루어 미분이 (ŷ - y)로 단순화됩니다. 잘못된 확신에 큰 페널티.
Categorical CE — 다중 분류
Softmax 출력과 결합해 K개 클래스 중 하나를 고르는 문제에 사용. one-hot 정답과 매칭.
직접 해보기 — 실습 과제
- 이상치 효과 관찰: 정답을 0으로 두고 예측을 2.5까지 움직여보세요. MSE는 6.25, MAE는 2.5 — 6배 가까운 차이가 발생합니다. 이상치가 많은 데이터에서 MSE 모델이 이상치에 끌려가는 이유입니다.
- Huber의 절충 효과: 정답 근처(예: 예측 0.5)에서 Huber와 MSE는 거의 같습니다. 예측을 멀리(2.0+)로 옮기면 Huber가 MAE처럼 선형이 됩니다. 두 모드의 전환점이 δ=1.0입니다.
- Cross-Entropy의 발산: 분류 모드에서 정답 1로 두고 예측을 0.001로 옮겨보세요. BCE가 약 6.9까지 치솟습니다 — log 발산이 잘못된 확신을 강력하게 처벌합니다.
- 학습 신호 비교: 정답 1에서 예측 0.5일 때 BCE ≈ 0.69, MSE = 0.25. 같은 오차라도 BCE가 더 큰 학습 신호를 제공합니다.