
넘스탯
DATA ANALYTICS & INSIGHTS
확률에서 LLM까지 – 데이터 사이언스 전문 교육 플랫폼
모델 평가 실습실
"측정할 수 없으면 개선할 수 없다" — 분류·회귀 모델의 성능을 정확히 평가하는 방법
원하는 개념·랩·가이드를 검색해보세요
Ctrl K정확도 99%가 왜 나쁜 모델일 수 있을까
이 페이지에서 배우고 나면
- 정확도만으로는 왜 부족한지(불균형 데이터의 함정) 실험으로 이해할 수 있습니다.
- 정밀도·재현율·F1·AUC가 각각 무엇을 재는지 직접 비교할 수 있습니다.
- 혼동 행렬을 읽고 모델이 어떤 실수를 하는지 파악할 수 있습니다.
혼동 행렬과 5대 평가 지표
혼동 행렬(Confusion Matrix)은 분류 결과를 TP/FP/FN/TN 네 칸으로 분해합니다. 이 네 숫자로부터 Accuracy, Precision, Recall, Specificity, F1이 모두 도출됩니다. 어떤 지표를 최우선으로 볼지는 도메인의 오류 비용 구조에 달려 있습니다.
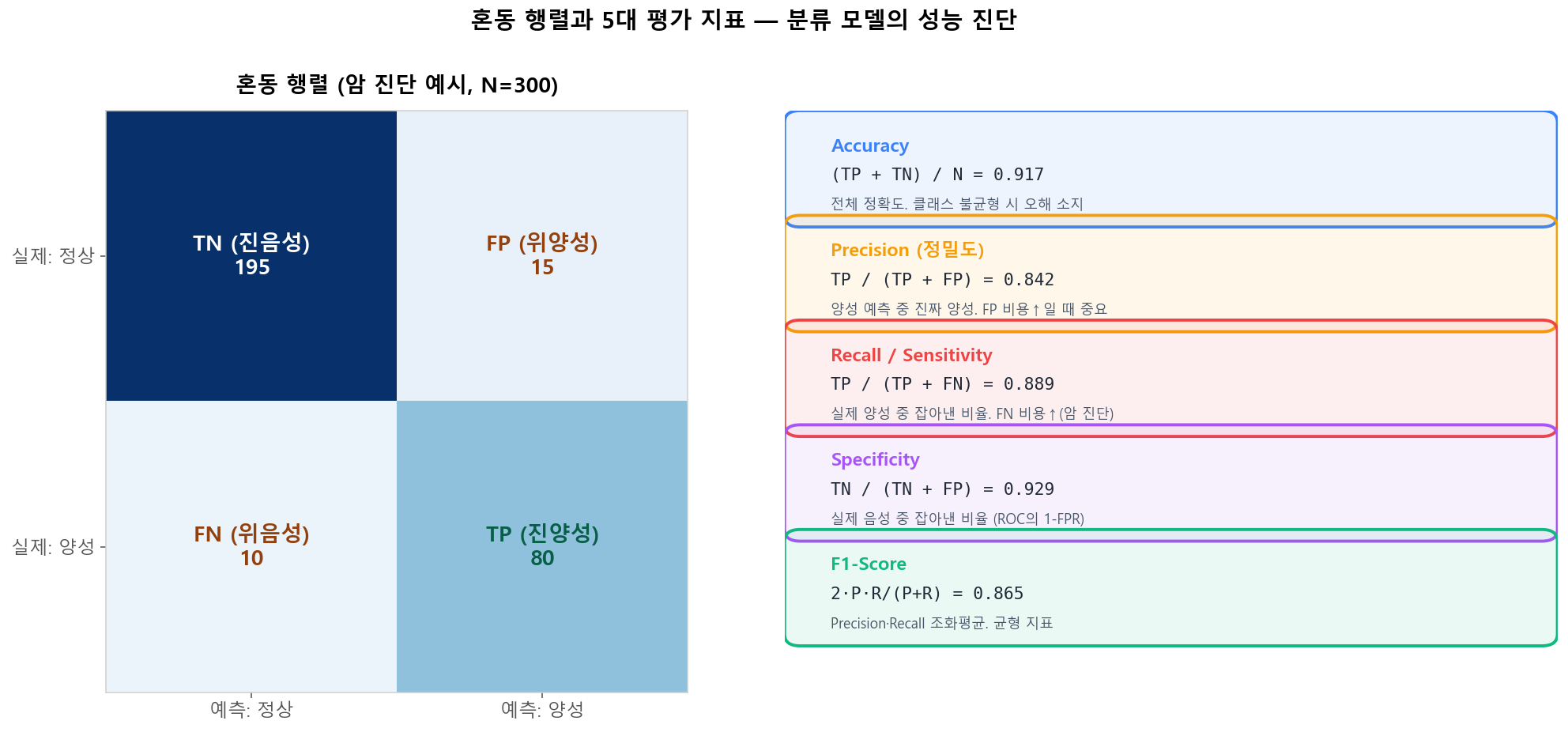 혼동 행렬과 5대 지표 — 분류 모델 성능 진단의 출발점
혼동 행렬과 5대 지표 — 분류 모델 성능 진단의 출발점ROC Curve와 AUC
ROC 곡선은 모든 임계값에서의 (FPR, TPR)을 그린 것으로, 임계값과 무관하게 모델 자체의 분류 능력을 평가합니다. AUC(Area Under Curve)는 무작위로 뽑은 양성 샘플의 점수가 무작위로 뽑은 음성 샘플보다 높을 확률 — 0.5는 무작위, 1.0은 완벽.
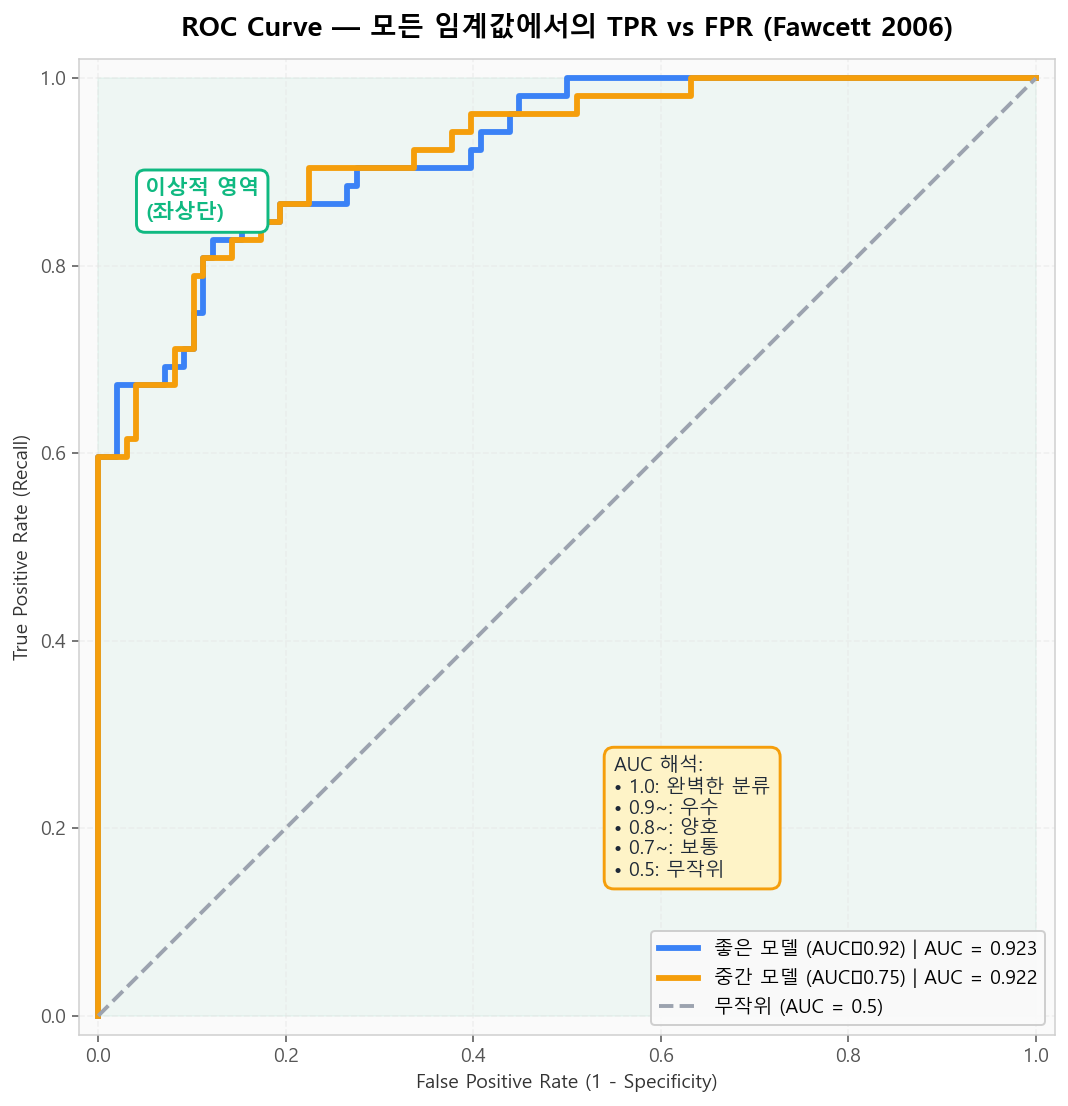 ROC Curve — Fawcett (Pattern Recognition Letters 2006)
ROC Curve — Fawcett (Pattern Recognition Letters 2006)모델 평가 인터랙티브 — 임계값 ↔ 혼동행렬·Precision·Recall·F1·ROC
이진 분류기의 출력 확률을 가정하고 분류 임계값을 조절하며 5대 지표와 ROC 곡선 위 현재 위치를 실시간 관찰하세요.
분류 임계값 = 0.50
임계값을 낮추면 → 양성 예측↑ (Recall↑, Precision↓), 높이면 반대혼동 행렬 (Confusion Matrix)
59
141
72
28
ROC Curve (AUC = 0.222)
K-Fold 교차 검증
데이터를 K등분해 각 fold가 한 번씩 validation 역할을 합니다. K번 평균 성능으로 평가하면 단일 분할의 우연성을 제거하고 표준편차로 안정성까지 측정할 수 있습니다. K=5 또는 K=10이 표준이며, 작은 데이터에선 LOOCV(K=N)도 사용합니다.
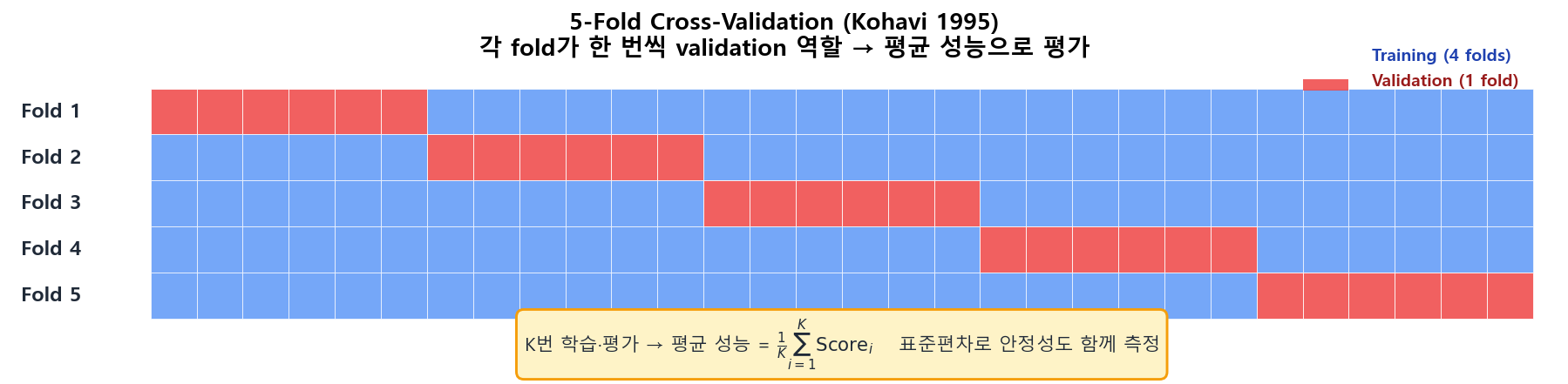 5-Fold Cross-Validation — Kohavi (IJCAI 1995)
5-Fold Cross-Validation — Kohavi (IJCAI 1995)Train/Val/Test 분할 + 과적합 진단
Training(모델 학습) · Validation(튜닝·모델 선택) · Test(최종 평가, 한 번만)로 분리해 data leakage를 방지합니다. 학습 곡선에서 훈련 손실은 계속 감소하지만 검증 손실이 다시 상승하면 과적합 — Early Stopping 지점입니다.
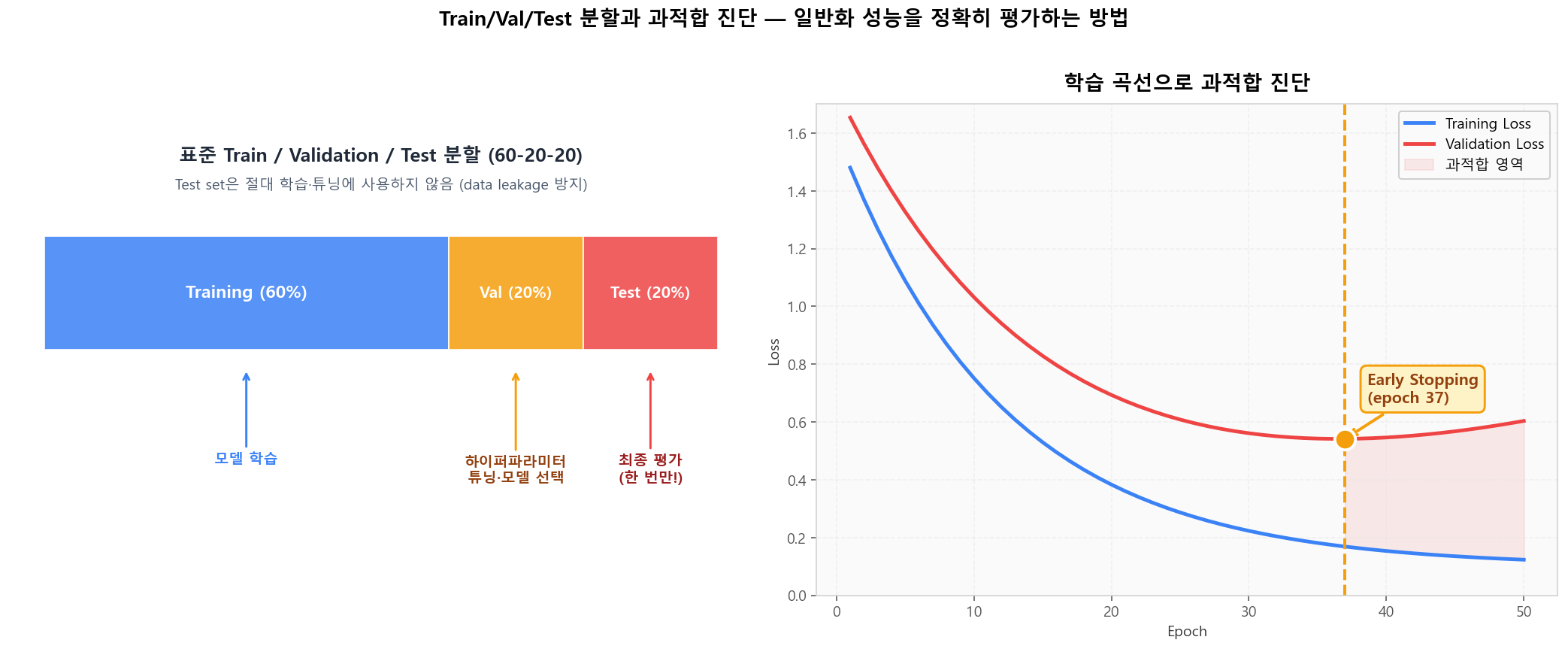 Train/Val/Test 분할과 학습 곡선으로 과적합 진단
Train/Val/Test 분할과 학습 곡선으로 과적합 진단Precision-Recall Curve — 불균형 데이터의 진실
양성 비율이 5% 같은 극심한 불균형 데이터에서는 ROC-AUC가 부풀려 보입니다. PR Curve와 Average Precision(AP)이 더 솔직한 평가입니다 (Saito & Rehmsmeier, PLOS ONE 2015). 사기 탐지·희귀 질병 진단처럼 양성이 드문 도메인에서 필수.
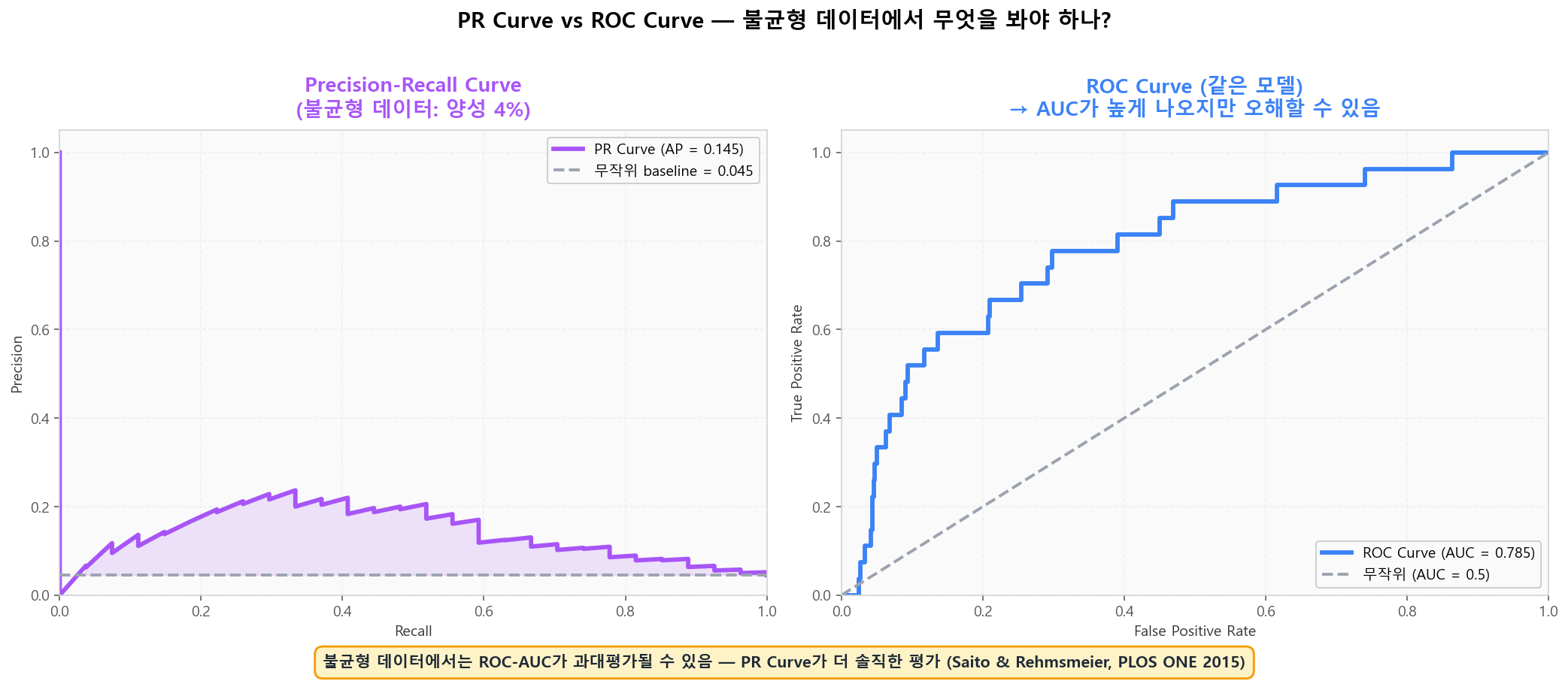 PR Curve vs ROC Curve — 불균형 데이터에서 어떤 것을 봐야 하나?
PR Curve vs ROC Curve — 불균형 데이터에서 어떤 것을 봐야 하나?도메인별 핵심 지표 선택
🏥 의료 진단 → Recall 우선
놓치면(FN) 환자 생명에 영향. 위양성(FP)은 추가 검사로 확인 가능.
📧 스팸 필터 → Precision 우선
정상 메일을 스팸으로 분류(FP)하면 사용자 손해. 약간의 FN(스팸 통과)은 감수 가능.
💳 사기 탐지 → PR Curve + Recall
양성(사기)이 0.1%로 극심한 불균형. ROC-AUC는 부풀려 보임 → PR-AUC 사용.
일반 분류 → F1 + Accuracy
균형 잡힌 데이터에서는 F1으로 종합 평가. Accuracy로 직관적 비교.
직접 해보기 — 실습 과제
- 임계값 0.5의 함정: 임계값을 0.5에서 0.3 → 0.7로 옮기며 Precision·Recall의 시소 관계 관찰. "최적 임계값은 도메인에 따라 다르다"
- F1의 균형점 찾기: 임계값을 천천히 옮기며 F1이 최댓값이 되는 지점 찾기. Precision과 Recall의 절충안
- ROC 곡선 위 이동: 임계값을 0→1로 옮기면 빨간 점이 (0,0)→(1,1)로 ROC 곡선을 따라 이동
- AUC의 임계값 무관성: 임계값을 어떻게 바꿔도 AUC는 변하지 않음. 모델 자체의 분류 능력 지표
- 의료 vs 스팸 시뮬레이션: 의료(Recall 우선) → 임계값 낮추기 / 스팸(Precision 우선) → 임계값 높이기. 같은 모델, 다른 운영점
📖 더 깊이 학습하기
- Hastie, Tibshirani, Friedman — Elements of Statistical Learning (Springer 2009) — Ch.7: 모델 평가·선택의 표준 교재
- Fawcett (Pattern Recognition Letters 2006): "An introduction to ROC analysis" — ROC 가이드
- Kohavi (IJCAI 1995): "A study of cross-validation and bootstrap" — CV 표준
- Saito & Rehmsmeier (PLOS ONE 2015): ROC vs PR Curve 비교 (불균형 데이터)
- scikit-learn 문서:
sklearn.metrics,sklearn.model_selection